A100 vs H100 vs B200 for LoRA fine-tuning and inference: a cost benchmark

You are about to fine-tune a 31-billion-parameter model and then serve it. The first decision you hit is which GPU to rent: the familiar A100, the faster H100, or the new B200. The instinct is that the newest chip must be the expensive one and the old chip must be the cheap one. We measured it, and that instinct is mostly wrong.
We ran the same LoRA fine-tuning and inference workload for google/gemma-4-31B-it on 8× A100, 8× H100, and 8× B200, swept the quantization and serving settings on each, and normalized everything to cost per token. The headline has two parts. First, when each platform is tuned, the cost per token lands within about 5% of the others — so price-per-token is effectively a tie, and it should not be what decides your choice. Second, once cost is a wash, the decision comes down to speed and to how much you can actually serve — and on both, the newer B-series pulls ahead, the more so as you scale across multiple GPUs. That is the lens we use throughout.
This post walks through what we found, with numbers you can act on. If you want the hands-on steps before the economics, our guide to fine-tuning Gemma 4 in 15 minutes covers the setup end to end.
TL;DR
- Cost per token is a near-tie (~5%) across A100, H100, and B200 once each is tuned — so price-per-token should not decide your GPU. Speed and serving capacity should, and there the B-series (B200) wins.
- Training: B200 finishes the same run in about a fifth of the GPU-hours. FSDP without gradient checkpointing beats the DDP default, and FP8 only helps via Transformer Engine +
torch.compileon Blackwell — naive FP8 is actually slower. - Inference: B200 serves over 10× the tokens per second of an A100 (partly FP8 vs bf16 and memory capacity, not pure silicon). The single biggest win is an FP8 KV cache (+44–57%); speculative decoding's sweet spot is a draft length of two.
- LoRA + speculative decoding ship together — acceptance stayed within 0.3 percentage points of the base model. That holds because LoRA stays close to the base; a full fine-tune may need its draft model updated.
- Everything here is an 8-GPU result. FSDP and high-concurrency serving need multiple GPUs, so provision multi-GPU nodes to capture these economics.
- Bottom line: default to the B-series on multi-GPU nodes for both training and inference; step down to H100 or A100 only where the workload allows.
The setup
We kept the workload identical across hardware so the comparison is fair:
- Model:
google/gemma-4-31B-it, fine-tuned with LoRA (rank 16, alpha 32, applied to all seven attention and MLP projections per layer). - Training data: a ShareGPT subset, packed to a sequence length of 2,048.
- Inference: served with vLLM on 1,000 ShareGPT prompts, using the FP8 build of the model for the H100 and B200 runs.
- Hardware: 8× A100 (bf16), 8× H100 (fp8), 8× B200 (fp8), eight GPUs per run.
- Cost: every cost number below is a relative index. We normalize so that the best-configured A100 run equals 1.00. No absolute dollar figures appear here.
Two workloads, two stories. Let's start with training.
Training: speed and cost are different questions
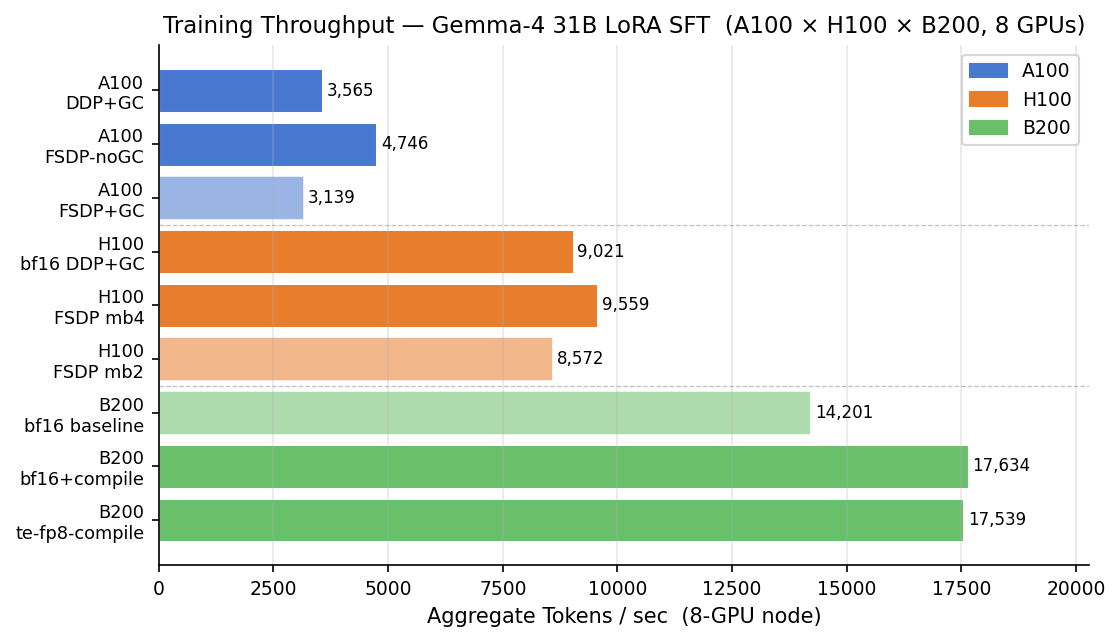
On raw training throughput, the ranking is exactly what you would expect. Measured in tokens per second, B200 runs about 4.0× faster than A100 and 1.6× faster than H100, and H100 runs about 2.5× faster than A100. If your goal is to finish a training run as fast as possible, the B200 wins outright: its best configuration completes a 220-step run in about a fifth of the GPU-hours the A100 baseline needs.
Cost per token is a different question, because faster hardware also bills more per hour. When you normalize for that, the picture flattens out dramatically:
| Best config per platform | Throughput (tokens/s) | Relative cost / token |
|---|---|---|
B200 — bf16 + torch.compile | 17,634 | 1.05 |
| H100 — FSDP + checkpointing, micro-batch 4 | 9,559 | 1.04 |
| A100 — FSDP, no gradient checkpointing | 4,746 | 1.00 |
| A100 — standard DDP + checkpointing | 3,565 | 1.33 |
The cost column barely moves: tuned, the A100, H100, and B200 all land within about 5% per token, with the A100 fractionally lowest only when it is perfectly configured. So read this table by the throughput column instead. The B200 does the same training run in a fraction of the wall-clock time — which teams actually feel as less waiting, faster iteration, and fewer days holding a reservation. Cost being a tie is the point: with the B-series you get that speed without paying more per token. (These are 8-GPU numbers, and even the cheapest A100 config only reaches the frontier by sharding the model across all eight GPUs — more on that next.)
FSDP beats the obvious default
The standard way to fine-tune on eight GPUs is data-parallel (DDP) with gradient checkpointing turned on to save memory. We found that fully sharded data-parallel (FSDP) without gradient checkpointing is faster and cheaper on both A100 and H100. Sharding the parameters across ranks frees enough memory that you can drop gradient checkpointing entirely and process larger micro-batches.
The effect is large. A100 FSDP without checkpointing hits 4,746 tokens/s, a third faster than the 3,565 you get from the DDP default. On H100, FSDP with a micro-batch of 2 reaches 8,572 tokens/s using only 7.6 GB per GPU, versus about 60 GB for the DDP setup — same throughput budget, a fraction of the memory.
FP8 training is a trap unless you do it right
FP8 sounds like free money: half the bytes, so it should be faster and cheaper. It is not, unless you use the right FP8 path.
- Naive FP8 on B200 ran at 0.48× the throughput of bf16 and used 2.2× the memory. It is slower and hungrier than just using bf16.
- FP8 on H100 was similarly counterproductive for training — bf16 was the cheaper choice.
- Transformer Engine FP8 with
torch.compileon B200 is the exception: it delivered the fastest wall-clock of any configuration we tested, at +23% throughput over bf16.
The takeaway: for training, reach for FP8 only through Transformer Engine plus torch.compile on Blackwell. Everywhere else, bf16 with FSDP is the cost-efficient default.
Is the training stable across hardware?
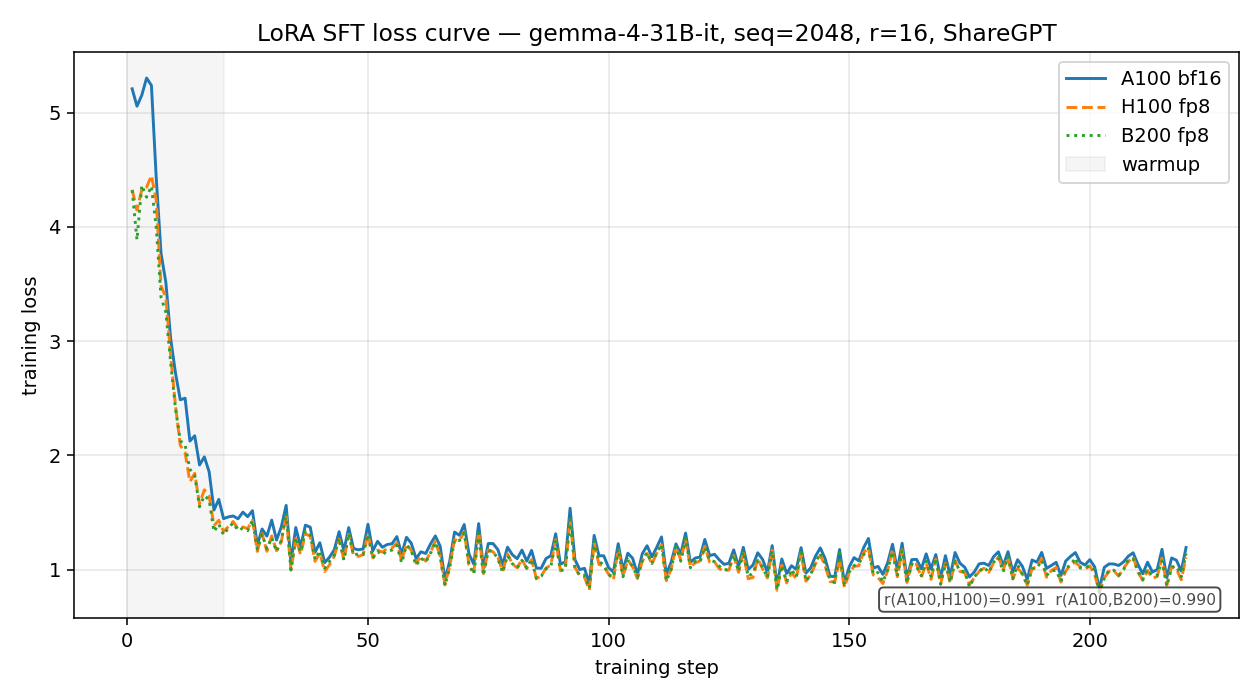
All three platforms converge to a similar final loss (1.11 to 1.19), so the trained adapter is comparable wherever you run it. The differences appear during warmup. The A100 run showed the largest gradient-norm spike (a peak of about 1,650 in the first 30 steps) and the most gradient anomalies, while H100 and B200 stayed an order of magnitude calmer (peaks near 220 to 235). None of the runs diverged, but if you fine-tune on A100, keep the warmup conservative and watch the first 30 steps.
Inference: this is where the new hardware earns its keep
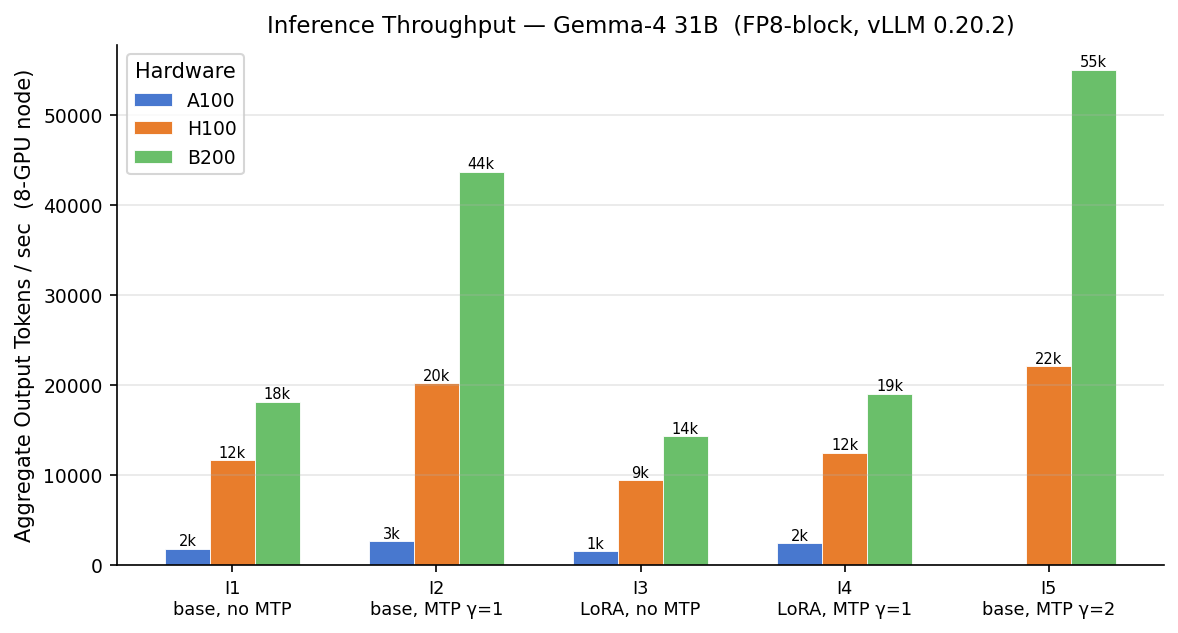
If training cost was a near-tie, inference is a blowout. On base throughput with no extra tricks, B200 serves 10.2× more tokens per second than A100, and H100 serves 6.5× more. Inference is bound by memory bandwidth, and that is exactly where the newer chips pull ahead. The practical consequence is that the per-token cost gap on inference is wide — H100 serves this model roughly 3 to 5× cheaper than A100 — and concentrating inference on newer hardware pays off far more than it does for training.
One honest caveat on that 10× figure: it is a real, deployable difference, but it is not pure silicon. Two things widen the gap. First, the A100 runs in bf16 while the H100 and B200 run in FP8, because the A100 has no native FP8 support — FP8 roughly halves memory traffic, so part of the lead is precision, not hardware. Second, these are aggregate numbers at each platform's best concurrency, and the A100's 80 GB leaves only about 10 GB for the KV cache after the model weights, so it saturates at far lower concurrency while the B200's 192 GB keeps scaling. The comparison reflects what you can actually run on each card — which is the number that matters for your bill — rather than isolating raw chip speed. Read it as a cost-and-capacity result, not a clock-speed one.
Two optimizations matter more than the hardware choice itself.
Speculative decoding (MTP), and yes, it works with LoRA
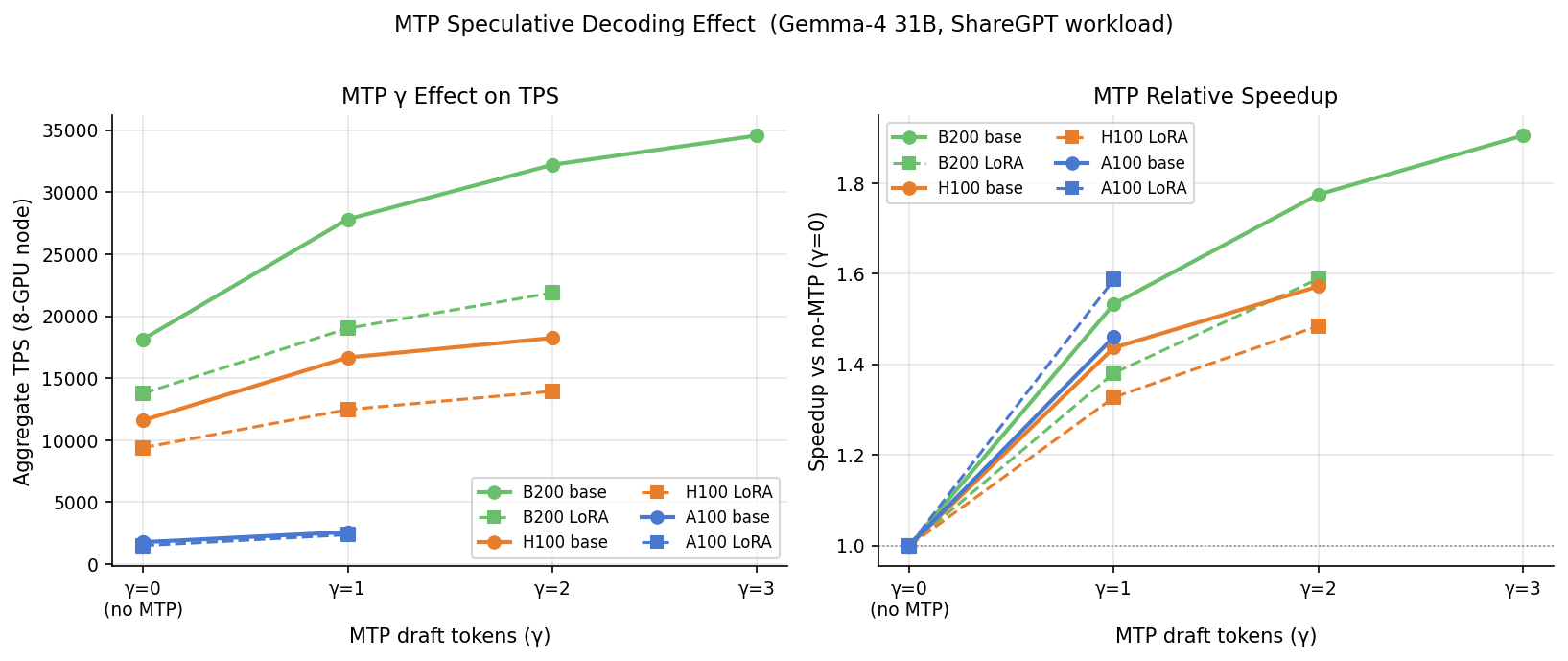
Multi-token prediction (MTP) lets the model draft several tokens ahead and verify them in one pass. Drafting one token ahead raised B200 throughput by 53% at an 82.8% acceptance rate. A second draft token added another 16%, but acceptance dropped to 73%. A third token added only 7% more. The practical sweet spot is a draft length of two.
The question we most wanted to answer: does speculative decoding still work when you hot-load a LoRA adapter? It does — and that was not a given. The draft model is the unmodified base model, so fine-tuning could have pulled the target's outputs away from the draft and dragged the acceptance rate down. With LoRA it barely moved: the gap between the base and LoRA models stayed within 0.3 percentage points on every platform, holding near 83% at a draft length of one. The reason is that a rank-16 LoRA adapter keeps the model close to the base the draft was built from, and the rate held across all three GPUs and matched a separate run on the same model. You can ship LoRA and speculative decoding together.
One scope note worth being honest about: this holds because it is LoRA. A full fine-tune updates every weight and can move the model much further from the base draft, so the acceptance rate — and with it the speculative-decoding speedup — would likely be lower unless you also retrain or swap the draft model to match. We measured LoRA only, so treat full fine-tuning as an open question rather than a guaranteed carry-over.
FP8 KV cache is the single highest-impact setting
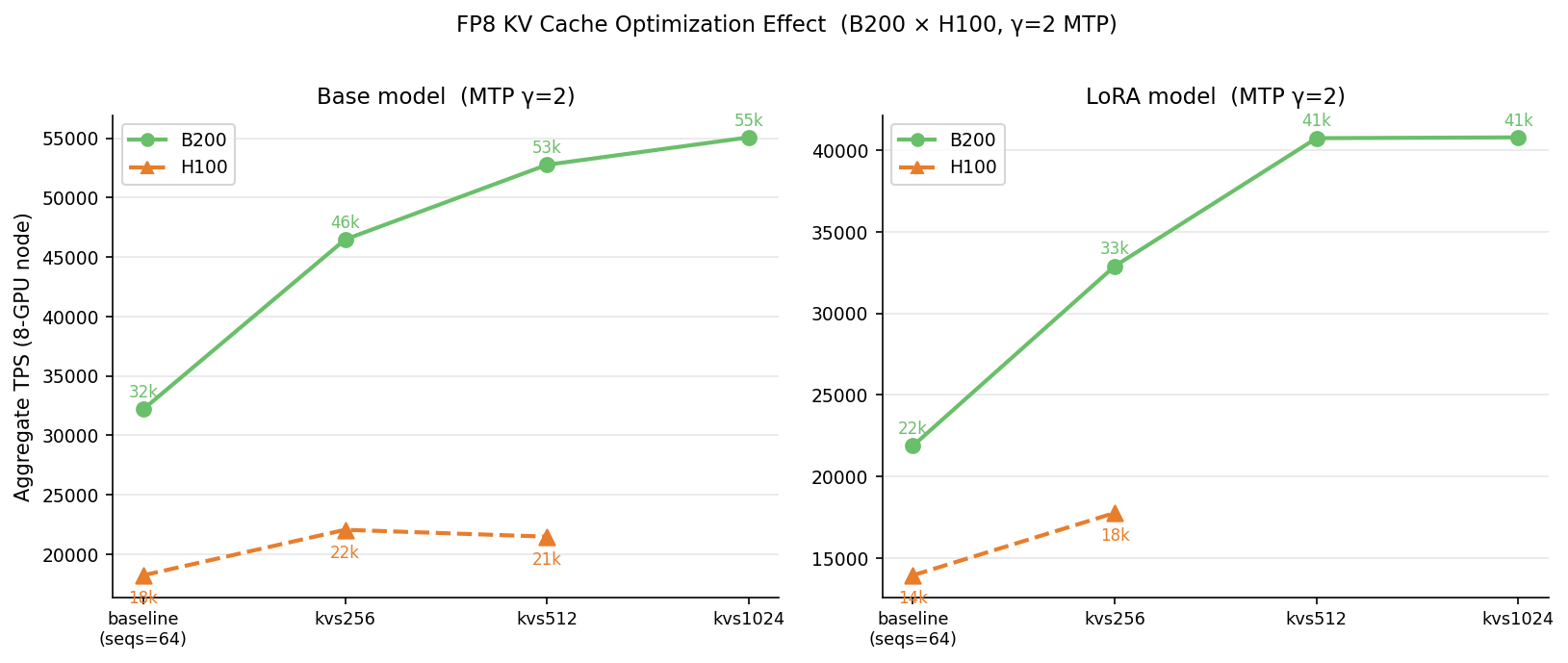
Storing the KV cache in FP8 halves its memory footprint, which lets you serve far more sequences at once. This was the largest single improvement in the entire study: between +44% and +57% throughput on top of an already-optimized setup. On B200, combining LoRA, a draft length of two, and an FP8 KV cache with 512 concurrent sequences reached 40,734 tokens/s — higher than the un-optimized base model. The optimizations more than paid for the LoRA serving overhead.
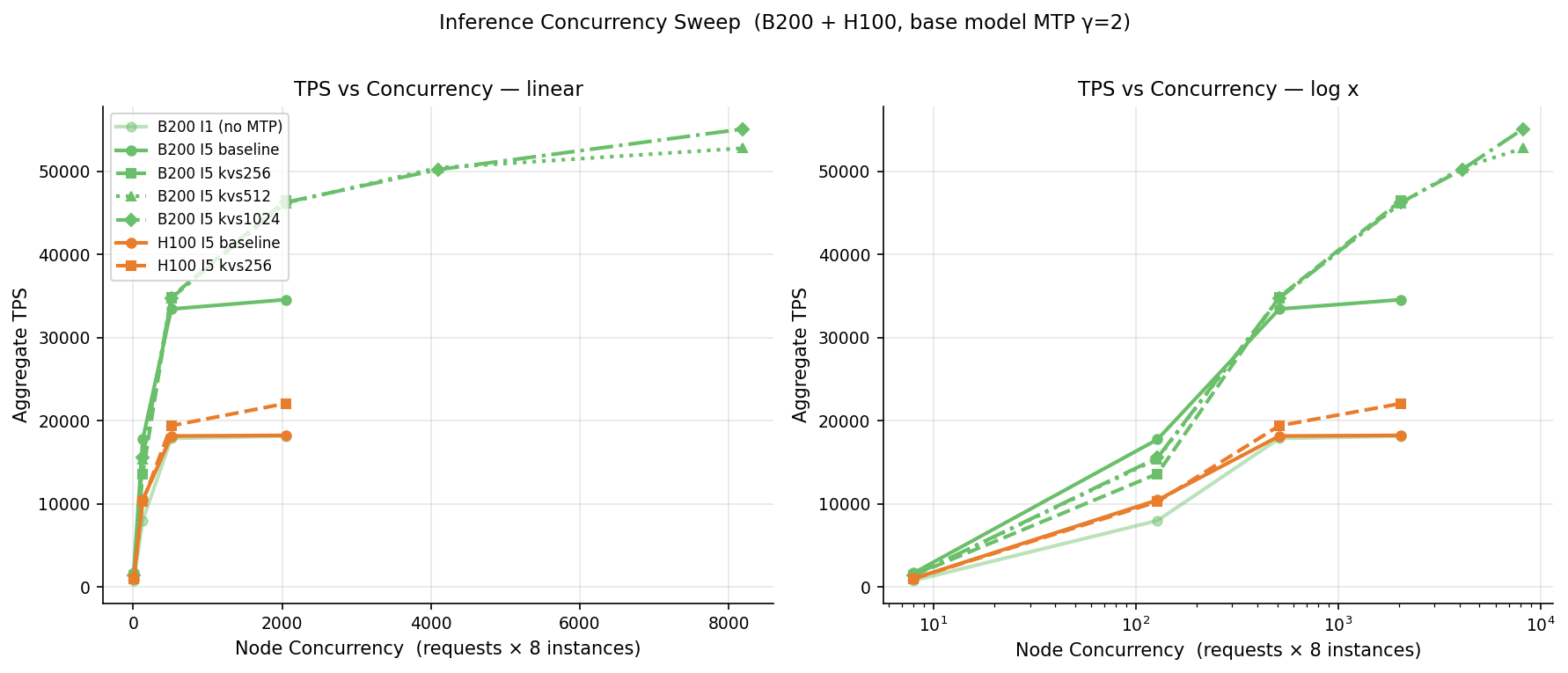
The FP8 KV cache also moves the saturation point to the right. B200 throughput kept climbing past 8,000 concurrent sequences, reaching 52,759 tokens/s, while the H100 saturated earlier — its 80 GB of memory tops out around 256 concurrent sequences. There is a latency cost: at 512 sequences, time-per-output-token sits around 192 ms, which is fine for batch workloads. Push to 1,024 and latency climbs to 331 ms with no extra throughput, so 512 is the practical ceiling for batch serving and 256 is the better choice when you need interactive latency.
What this means for your GPU choice
Here is how we would choose, in order:
- Start with the B-series (B200). Cost per token is a tie, so the tiebreakers are speed and serving capacity — and the B200 wins both. It trains the same job in a fraction of the wall-clock time and serves more than 10× the tokens per second of an A100, with the headroom (192 GB, native FP8, FP8 KV cache) to keep scaling as your traffic grows. For most teams this is the right default for both training and inference.
- Step down to H100 only when you don't need that ceiling. It still delivers 2.5× the training throughput and 6.5× the inference throughput of an A100 and serves far cheaper per token — a sensible middle tier when the B200's headroom is more than the workload calls for.
- Treat A100 as the cost floor. Perfectly tuned it is fractionally the cheapest per training token, but it is the slowest, has no native FP8 path, and its 80 GB saturates at low concurrency — so it cannot reach the inference numbers the newer cards do. Good for budget-bound or latency-tolerant training; not where you want production inference.
- Scale across GPUs, not on one. Every result here is an 8-GPU number. The cheapest training configs only reach the frontier because FSDP shards the model across all eight GPUs, and the largest inference wins — high concurrency, FP8 KV cache scaling past 8,000 sequences — only appear when you serve across multiple GPUs. A single GPU cannot even hold a 31B model comfortably, and leaves most of this throughput on the table. Provision multi-GPU nodes (up to 8 GPUs) to actually capture these economics.
Choosing hardware beyond these three? Our 2026 GPU selection guide maps the full lineup from L40S to B300 against workload types.
Run this on the right GPU without overpaying
The catch with all of this is access — to the newest chips, in multi-GPU nodes, when you need them. That is what VESSL Cloud is built for. VESSL AI is a neocloud for AI workloads, leading with the B-series (B200, GB200, B300) alongside H100 and A100 on one platform, multi-GPU nodes up to 8 GPUs per node, and Smart Pausing so idle environments stop billing. Run training and production inference on B200-class nodes, step down to H100 or A100 only where the workload allows, and scale across GPUs without juggling three vendors. If you're weighing the bill against the big clouds, we also broke down how neocloud and hyperscaler GPU pricing compare.
Not sure which GPU fits your model and budget? You don't need exact specs to start the conversation — tell us your workload and we'll suggest the realistic options. Talk to our team.
FAQ
Which GPU should I pick to fine-tune a model this size?
Default to the B-series (B200). Cost per token is within about 5% across all three when each is tuned, so it should not decide the choice — and on the things that do, speed and serving capacity, the B200 wins, training fastest and serving more than 10× the tokens per second of an A100. Step down to H100 when you don't need that ceiling, and use A100 as a budget floor for training. Provision multiple GPUs either way: these efficiencies are 8-GPU results, not single-GPU ones.
Does FP8 always make training cheaper?
No. Naive FP8 on B200 ran at 0.48× the throughput of bf16 and used 2.2× the memory, and FP8 on H100 was also slower than bf16 for training. The only FP8 path that helped was Transformer Engine plus torch.compile on B200, which gave the fastest wall-clock overall. Everywhere else, bf16 with FSDP is the cost-efficient default.
Can I use speculative decoding with a LoRA adapter?
Yes. The speculative-decoding acceptance rate with a hot-loaded LoRA adapter stayed within 0.3 percentage points of the base model on every platform. LoRA and multi-token prediction ship together cleanly — a draft length of two is the practical sweet spot.
What is the single highest-impact inference setting?
Storing the KV cache in FP8 and raising the concurrent-sequence limit. It added 44% to 57% throughput on top of an already-tuned setup — the largest single win we measured. Use 512 concurrent sequences for batch workloads and 256 when you need interactive latency.
References
- google/gemma-4-31B-it on Hugging Face
- vLLM speculative decoding documentation
- NVIDIA H100 and NVIDIA B200 product pages
- VESSL Cloud pricing
VESSL AI