GPU 비용 낭비 없이 4배 빠르게: 안드레 카파시의 Autoresearch 활용 방법

TL;DR
- Andrej Karpathy의
autoresearch(오토리서치)는 AI 에이전트가 스스로 코드를 고치고 학습을 반복하며 모델 성능을 끌어올리는 오픈소스 프레임워크입니다. - 이를 단일 GPU에서 순차적으로 실행하면 시간이 오래 걸리지만, VESSL Cloud의 Job 기능을 활용해 병렬(fan-out)로 실행하면 추가 비용 없이 전체 소요 시간(wall time)을 4배 단축할 수 있습니다.
- 실험 셋업: nanochat에서 따온 ~50M 파라미터 GPT를 ClimbMix corpus로 프리트레이닝(pretraining)한 경우입니다.
Karpathy의 autoresearch가 보여준 아이디어는 명쾌해요. AI 에이전트가 직접 train.py를 수정하고 학습을 돌려요. 결과(val_bpb)가 좋아지면 반영하고, 아니면 되돌리죠. 이 과정을 16번만 반복해도 기존 베이스라인 모델의 성능을 가볍게 뛰어넘을 수 있어요.
문제는 실험 환경이에요. GPU 한 장에서 16번의 실험을 순차적으로 돌리면 2시간 가까이 걸려요.
하지만 VESSL Cloud에서는 똑같은 알고리즘을 돌리더라도 이 시간을 40분으로 단축할 수 있어요. 결과적으로 같은 비용에 4배 더 많은 실험을 처리하게 되죠. 똑같은 H100 GPU를 쓰고, 시간당 비용도 $2.39, 총 비용 $5.28로 전부 똑같아요. GPU가 갑자기 빨라진 게 아니에요. 스케줄링 방식을 바꿨을 뿐이죠.
왜 속도 차이가 날까요?
순차적 실행을 알고리즘의 필수 조건이라 착각하기 쉬워요. 하지만 이건 단순히 하드웨어의 제약일 뿐이에요. 내 PC에 GPU가 한 장밖에 없으니 어쩔 수 없이 하나씩 돌렸던 거죠. 물론 모델을 개선해 나가는 각 "라운드"는 이전 결과를 보고 다음 방향을 정해야 하니 순서가 중요해요. 하지만 한 라운드 안에서 4가지 서로 다른 가설을 테스트할 때는 얘기가 다릅니다. 이 4개의 실험은 서로 아무런 영향을 주지 않아요. 굳이 하나씩 기다릴 필요 없이 4개를 한 번에 병렬로 학습시킨 뒤 가장 좋은 결과를 고르면, 똑같은 결과를 얻으면서도 시간은 훨씬 아낄 수 있죠.
단일 실험의 타임라인을 분해해 보면 병목이 명확히 보여요. 실제 GPU가 연산하는 학습 시간은 5분 남짓이지만, 그 앞뒤로 이미지 다운로드, JIT 컴파일, 로깅 등 GPU가 전혀 필요 없는 대기 시간이 3~4분이나 차지하거든요.
이걸 하나씩 순서대로 돌리면, 시간당 $2.39나 하는 비싼 H100 GPU가 전체 실행 시간의 절반 가까이를 그저 대기하는 데 쓰게 돼요. 16번의 실험이 누적되면 1시간 가까운 GPU 낭비가 발생하죠. 에이전트가 다음 코드를 고민하고 수정하는 시간까지 더하면 그 비효율은 훨씬 더 커져요.
클라우드 시대에 맞는 새로운 에이전트 활용법
"에이전트가 GPU 한 장을 24시간 내내 쓴다"는 건 이제 옛날 방식이에요. 클라우드 환경에서 에이전트는 GPU를 직접 관리하지 않아요. 실험 워크로드를 제출하고, ID(slug)를 받아 결과를 기다린 뒤 다음 실험을 실행하는 게 전부죠.
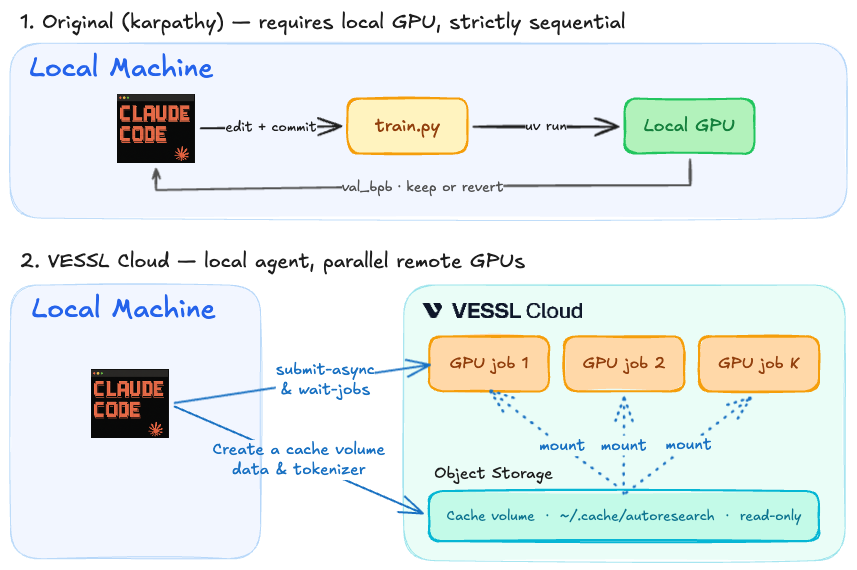
실제 VESSL Cloud Cookbook을 바탕으로 한 전체 워크플로우는 다음과 같이 흘러가요:
- 가설 설정 및 코드 수정: 에이전트가 아이디어를 내고
train.py를 수정해 K개의 서로 다른 가설(예: 하이퍼파라미터 조합)을 세웁니다. - 병렬 실험 제출: 에이전트가 CLI 도구를 통해 K개의 후보를 각각 독립된 VESSL Job으로 클라우드에 동시 제출합니다.
- 결과 수집 및 최적화: 클라우드에서 학습이 모두 끝나면, 에이전트가 가장 좋은 결과를 낸 설정을 확정하고 다음 라운드를 시작합니다.
이 흐름을 빠르고 저렴하게 만들기 위해 쿡북에 적용된 3가지 핵심 패턴을 살펴볼까요?
1. 데이터 준비는 한 번만 하세요. ~1GB ClimbMix 샤드를 prep 잡으로 한 번 받아서 Object storage(공유 저장소)에 올려두면, 이후 모든 학습 잡이 같은 볼륨을 read-only로 마운트해서 그대로 써요. 실험마다 매번 다시 받지 않아요.
2. 에이전트는 GPU를 몰라도 돼요. vesslctl job create 명령어로 실험을 제출하고 결과만 확인하면 돼요. 에이전트가 굳이 GPU를 직접 쥐고 있을 필요가 없어요.
3. 한 라운드 안의 K개 실험은 동시에 돌리세요. submit-async.sh로 K개의 실험을 한 번에 병렬로 던지고 wait-jobs.sh로 결과를 모으는 패턴이에요.
# K=4 candidate를 한 라운드에 동시 제출 → 모두 끝날 때까지 대기
slugs=()
for branch in "${CANDIDATE_BRANCHES[@]}"; do
git checkout "$branch"
slugs+=( "$(bash batch-job/submit-async.sh)" )
done
bash batch-job/wait-jobs.sh "${slugs[@]}"이렇게 하면 4개의 실험을 하나씩 차례대로 돌릴 때 ~40분이 걸리던 한 라운드를 ~10분짜리 실험 1번으로 끝낼 수 있어요. 시간당 약 28개 가설을 테스트할 수 있고, 순차적으로 ~7개 실험을 돌리는 것 대비 4배 빠른 속도예요.
실제 구현은 더 단순해요. VESSL Cloud CLI가 설치된 환경에서 에이전트가 vesslctl job create 명령어를 직접 실행할 수 있도록 프롬프트에 추가해 주기만 하면 끝이에요. 에이전트는 이 명령어로 실험을 제출하고 결과만 읽어오면 되거든요.
비용은 개별 실험당 GPU 점유 시간 합으로 계산되니까, 순차적으로 돌리든 4개씩 병렬로 돌리든 16번의 학습 시간 합이 같으면 청구 금액도 똑같아요. 줄어드는 건 전체 소요 시간뿐이에요.
비용 효율이 완전히 달라져요
여기서부터 계산이 완전히 달라져요. $1로 할 수 있는 실험 개수가 4배 늘어나는 거예요.
똑같은 H100, 똑같은 코드, 똑같은 데이터인데 아이디어를 검증하는 속도는 4배가 돼요. 병렬 실행(K)을 늘리면 속도는 더 빨라지고요. 전체 비용을 결정하는 건 동시성 한도(concurrency limit)지 GPU 장수가 아니니까요.
그러니 "GPU가 절반쯤 노는 건 어쩔 수 없다"는 생각은 이제 버려야 해요. 에이전트가 전용 GPU 인프라를 24시간 내내 점유할 필요가 없습니다. 대신 필요한 순간에 원하는 만큼 클라우드에 실험을 제출해 병렬로 처리하고, 끝난 결과만 모아서 받아오는 온디맨드(on-demand) 방식이 훨씬 효율적이에요.
에이전트에게 비싼 가격의 전용 GPU를 할당해주기 보다, 실험을 확장할 수 있는 작업 큐(Job queue)를 조정할 수 있게 해 주세요.
실제 실행 결과
실험 셋업은 nanochat에서 따온 ~50M 파라미터 GPT (12 layers, 768 hidden, vocab 32k)를 ClimbMix corpus로 pretraining하는 거예요. 단일 학습은 5분 time-budget, 평가는 val_bpb (bits per byte, 낮을수록 좋음).
H100 SXM 1장에서 K=4로 4라운드를 돌린 결과예요.
| Round | Knobs | val_bpb | 결과 |
|---|---|---|---|
| 1 | EMBEDDING_LR, WEIGHT_DECAY, WINDOW_PATTERN | 1.0107 | 베이스라인 유지 |
| 2 | WARMDOWN_RATIO, ADAM_BETAS, MATRIX_LR, WARMUP_RATIO | 1.0081 | MATRIX_LR 0.04 → 0.05 |
| 3 | DEPTH, ASPECT_RATIO, TOTAL_BATCH_SIZE | 0.9986 | TOTAL_BATCH_SIZE 2^19 → 2^18 |
| 4 | (c10 베이스) DEPTH, MATRIX_LR, WARMDOWN_RATIO, EMBEDDING_LR | 0.9856 | DEPTH 8 → 10 |
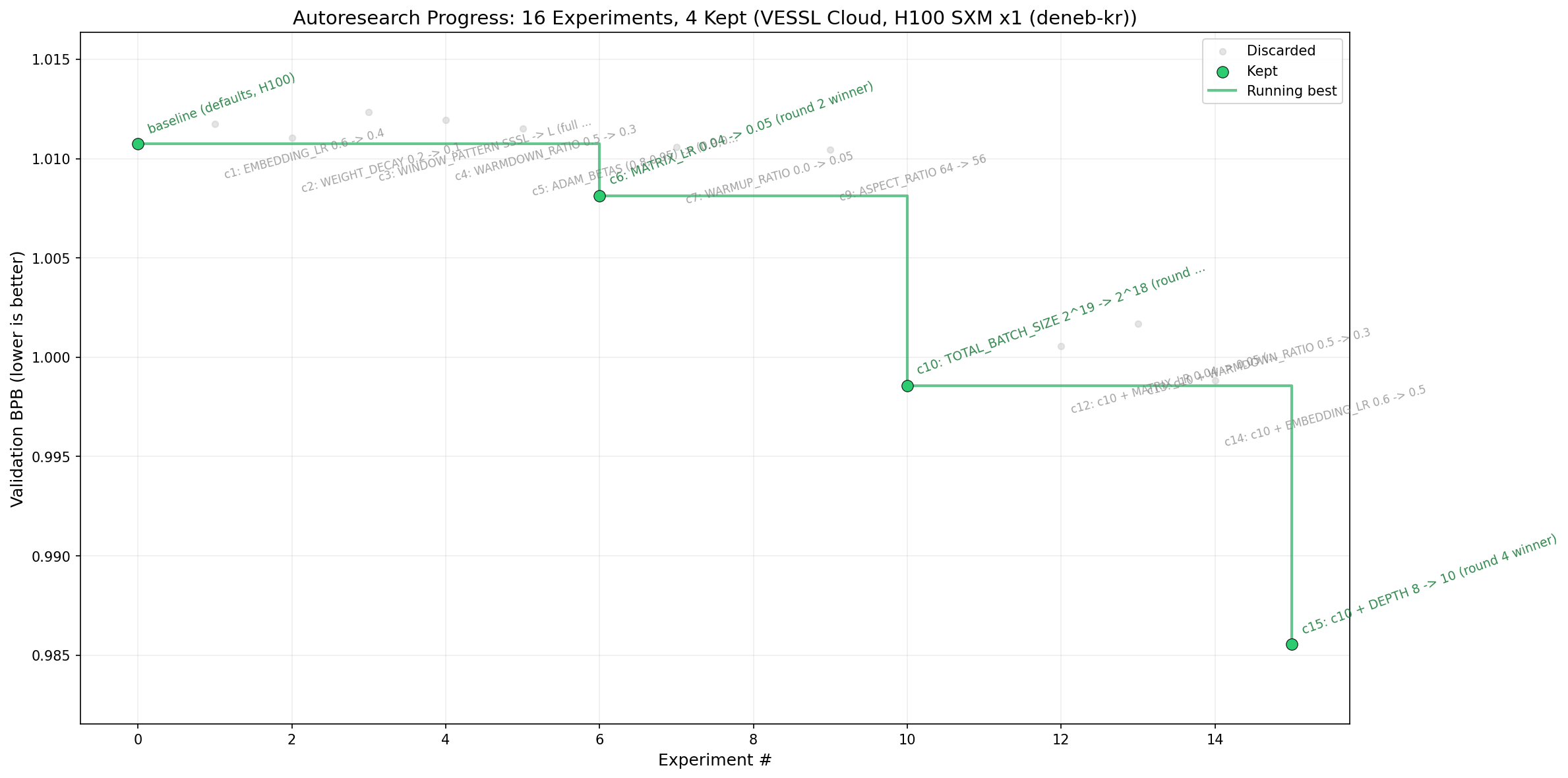
라운드 4에서 val_bpb 0.9856을 기록하며, karpathy의 레퍼런스 수치인 0.9979를 뛰어넘었어요. 총비용은 $5.28, 실제 소요 시간은 40분이었죠. 16개의 실험을 점심시간 안에 모두 끝낸 셈이에요.
직접 돌려보고 싶다면
이 패턴은 autoresearch에만 쓸 수 있는 게 아니에요. 하이퍼파라미터 스윕, NAS, 단일 GPU 학습 등 어디에나 똑같이 적용할 수 있어요.
블로그에서는 배경과 원리 위주로 설명했지만, 실제 환경에 적용하려면 구체적인 코드가 필요하겠죠. 전체 코드와 그대로 따라 할 수 있는 재현 스크립트는 VESSL Cloud Cookbook에 모두 준비해 두었어요. 처음 시작을 위한 VESSL Cloud 환경 설정 방법은 VESSL Cloud Docs 워크플로우 가이드를 참고해 보세요.
자주 묻는 질문 (FAQ)
K(병렬 실행 수)는 어떻게 정하나요?
워크스페이스의 리소스 한도(Quota)와 예산에 맞춰 정해요. 시작점으로는 비용 통제와 탐색의 다양성 사이에서 균형을 맞추기 좋은 K=4를 추천해요. 더 공격적으로 실험하고 싶다면 K=8까지 올려도 좋아요.
에이전트가 무한 루프에 빠져서 비용이 너무 많이 나오면 어쩌죠?
실험 환경에 최대 실행 시간을 걸어두고, 에이전트 코드 안에서도 최대 라운드 수를 명시하세요. 이 두 가지만 설정해 두면 예산 통제는 전혀 어렵지 않아요.
A100, L4 등 다른 GPU로 돌려도 되나요? (flash-attn 미지원 포함)
환경변수 AUTORESEARCH_RESOURCE_SPEC을 해당 단일 GPU 스펙으로 바꾸면 그대로 돌아가요. 단일 실험의 학습 시간만 길어질 뿐, 여러 개를 동시에 돌려서 얻는 스케줄링의 이점은 똑같습니다. (단, 다중 GPU 분산 학습은 train.py가 단일 GPU를 가정하고 있어 별도의 코드 수정이 필요합니다.)
Kubernetes(K8s)를 직접 쓰면 안 되나요?
가능해요. 하지만 이미지 다운로드 설정, 볼륨 연결, 작업 상태 확인, 에러 처리 로직을 직접 다 짜야 하죠. vesslctl job create 한 줄이면 이 모든 번거로운 작업이 사라집니다. 이게 바로 핵심이에요.
VESSL AI
뉴스레터 구독
AI 인프라 구축 노하우와 최신 GPU 소식을 매달 보내드려요.