15분 만에 끝내는 Gemma 4 파인튜닝


오픈소스 LLM, 내 데이터로 학습시키고 싶은데 어디서 시작하죠?
Google이 2026년 4월에 공개한 Gemma 4 E4B는 4B 파라미터로 MMLU Pro 69.4%, AIME 2026 42.5%를 기록했어요. 모델 크기 대비 성능이 뛰어나서 파인튜닝 입문용으로 딱 좋은 모델이에요.
문제는 환경이에요. 로컬 GPU가 없거나, Colab에서 세션이 끊기거나, 팀원과 모델을 공유하기 어렵거나.
이 글에서는 VESSL Cloud에서 Gemma 4를 파인튜닝하는 전체 과정을 다뤄요. 실제로 돌려본 벤치마크도 함께 공유할게요.
전체 코드는 쿡북에서 받으세요
데이터셋, LoRA 하이퍼파라미터, Jupyter 노트북, vesslctl 제출 스크립트까지 한 번의 클론(clone)으로 받을 수 있어요. VESSL Cloud Cookbook — Gemma 4 파인튜닝
실측 벤치마크 요약
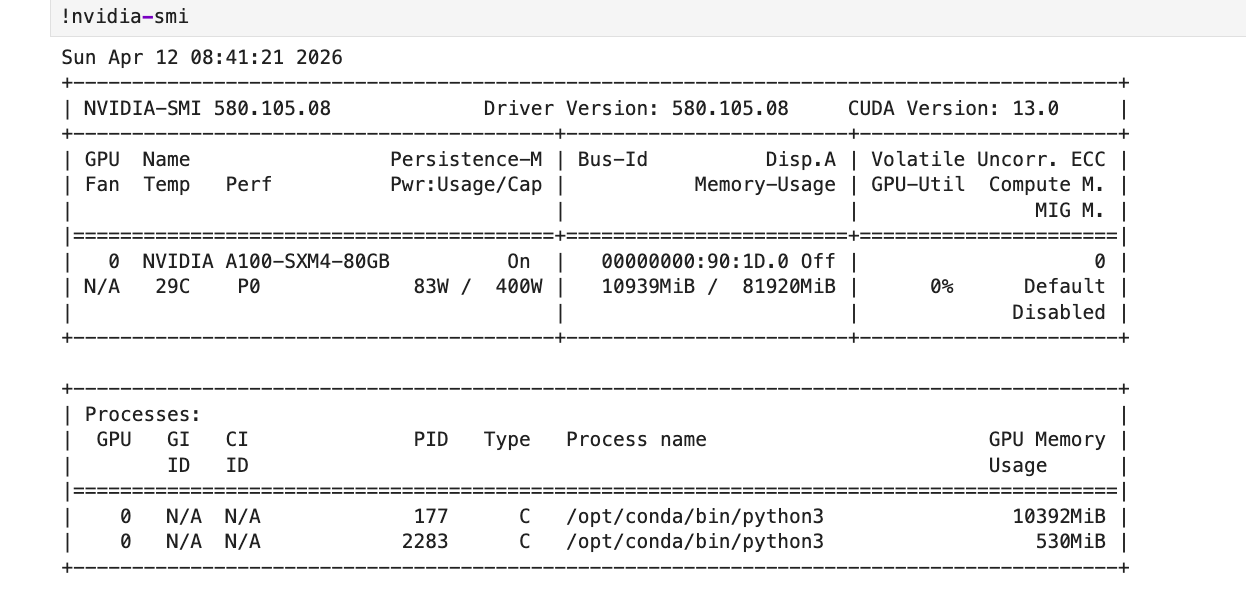
VESSL Cloud A100 SXM 80GB에서 직접 실험한 결과예요.
| 항목 | 실측값 |
|---|---|
| GPU | NVIDIA A100 SXM 80GB |
| 총 소요 시간 | 14분 38초 |
| 학습 시간 | 8분 16초 (60 steps) |
| 피크 VRAM | 10.12 GB / 80 GB |
| 총 비용 | $0.38 |
| 모델 | gemma-4-E4B-it (4-bit quantized) |
| 방법 | QLoRA (r=8, alpha=8) |
| 데이터셋 | FineTome-100k (3,000 samples) |
| Training Loss | 2.37 → 0.66 |
80GB VRAM 중 10GB만 썼어요. A100 SXM 시간당 $1.55 기준, 15분 학습에 $0.38이에요. 참고로 AWS에서 A100을 쓰려면 8장 번들(p4d.24xlarge, $21.96/hr)을 띄워야 해서 같은 15분 작업에 ~$7.32가 들어요.
시작하기 전에 알아두면 좋은 것들
파인튜닝이 뭔가요?
이미 학습된 모델(Gemma 4)에 내 데이터를 추가로 학습시키는 거예요. 처음부터 학습하면 수천 GPU-시간이 필요하지만, 파인튜닝은 기존 지식 위에 쌓는 거라 훨씬 적은 자원으로 가능해요.
QLoRA는 뭔가요?
모델 전체를 학습하는 대신, 작은 어댑터(LoRA)만 학습하는 방법이에요. 여기에 4-bit 양자화(Quantization)를 더한 게 QLoRA — VRAM 사용량을 크게 줄여서 A100 한 장으로도 충분해요.
Unsloth는 뭔가요?
LoRA 학습을 최적화해주는 라이브러리예요. 같은 하드웨어에서 약 1.5배 빠르고, VRAM을 60% 덜 써요.
Step 1: VESSL Cloud 워크스페이스 만들기
VESSL Cloud에 접속해서 워크스페이스 만들기 가이드를 참고해서 워크스페이스를 만들어요.
| 설정 | 값 | 이유 |
|---|---|---|
| GPU | A100 SXM 80GB | E4B QLoRA에 충분한 VRAM |
| GPU 수 | 1 | 싱글 GPU로 충분 |
| 이미지 | pytorch/pytorch:2.5.1-cuda12.4-cudnn9-devel | CUDA 12.4 포함 |
| Cluster Storage | /root에 마운트 | pip 패키지, 코드 영속 저장 |
| Object Storage | /shared에 마운트 | 모델 파일 크로스클러스터 공유 |
왜 스토리지를 두 개 마운트하나요?
- Cluster Storage (
/root): pip 패키지와 코드가 워크스페이스를 재시작해도 유지돼요. 같은 클러스터 내에서 빠른 I/O를 제공해요. - Object Storage (
/shared): 파인튜닝한 모델을 여기에 저장하면 다른 클러스터의 워크스페이스에서도 바로 접근할 수 있어요. 팀원과 모델을 공유할 때 가장 좋은 방법이에요.
Colab이나 로컬에서는 이런 워크플로우가 불가능하죠.
생성이 끝나면 이렇게 Workspaces 목록에서 확인할 수 있어요. GPU가 A100 SXM으로 잡혔는지 확인한 뒤 다음 단계로 넘어가요.
스토리지 생성 방법이 처음이라면 스토리지 개요를 먼저 확인해 주세요. Cluster Storage와 Object Storage를 각각 만든 뒤 워크스페이스에 마운트하는 거예요.
Step 2: 패키지 설치
워크스페이스가 Running 상태가 되면 JupyterLab에 접속해요. 터미널을 열고:
pip install unsloth
pip install --upgrade trl transformers datasetsCluster Storage에 /root를 마운트했기 때문에, 워크스페이스를 재시작해도 다시 설치할 필요 없어요.
Step 3: 모델 로딩
JupyterLab에서 새 Python 노트북을 만들고, 셀을 순서대로 실행하면 돼요.
from unsloth import FastModel
model, tokenizer = FastModel.from_pretrained(
model_name="unsloth/gemma-4-E4B-it",
max_seq_length=2048,
load_in_4bit=True, # 4-bit 양자화로 VRAM 절약
full_finetuning=False,
)load_in_4bit=True가 QLoRA의 핵심이에요. 모델 가중치를 4-bit로 압축해서 VRAM 사용량을 크게 줄여줘요. max_seq_length=2048은 입력 시퀀스 최대 길이예요. 더 긴 대화가 필요하면 4096으로 늘릴 수 있지만 VRAM이 더 필요해요.
Step 4: LoRA 어댑터 설정
model = FastModel.get_peft_model(
model,
finetune_vision_layers=False, # 텍스트만 학습
finetune_language_layers=True,
finetune_attention_modules=True,
finetune_mlp_modules=True,
r=8, # LoRA rank
lora_alpha=8,
lora_dropout=0,
bias="none",
random_state=3407,
)각 파라미터의 의미와 이 값을 고른 이유를 정리했어요. 처음 파인튜닝을 해보는 분도 이 표만 읽어도 왜 이 값을 선택했는지 감이 올 거예요.
| 파라미터 | 값 | 뜻 / 이 값을 쓴 이유 |
|---|---|---|
finetune_vision_layers | False | Gemma 4는 멀티모달 모델이지만 이번엔 텍스트만 학습할 거라 비전 레이어는 제외해요. |
finetune_language_layers | True | 언어 생성 품질에 직접 영향을 주는 레이어라 학습 대상에 포함해요. |
finetune_attention_modules | True | 문맥 파악을 담당하는 어텐션 모듈을 학습해요. |
finetune_mlp_modules | True | 지식과 표현력이 저장된 MLP 모듈을 학습해요. |
r | 8 | LoRA rank — 학습할 어댑터의 "용량". 작으면 가볍고 빠른 대신 표현력이 제한돼요. 단순 스타일 학습엔 8로 충분하고, 복잡한 태스크엔 16이나 32로 올려요. |
lora_alpha | 8 | LoRA 출력 스케일링 팩터예요. 보통 r과 같거나 2배로 두면 안정적이에요. |
lora_dropout | 0 | 과적합 방지용 드롭아웃이에요. 3,000개 소량 데이터에는 0으로 둬도 충분하고, Unsloth 최적화 시에도 0을 권장해요. |
bias | "none" | 바이어스 파라미터는 학습 대상에서 제외해 VRAM과 학습 파라미터 수를 줄여요. |
random_state | 3407 | 재현성을 위한 시드 값이에요. 숫자 자체는 임의지만 고정해두면 다음에 돌려도 같은 결과가 나와요. |
더 복잡한 태스크(예: 코드 생성, 전문 도메인 지식)를 학습시키려면 r을 16 또는 32로 올리고, lora_alpha도 같이 올려주면 돼요.
Step 5: 데이터셋 준비
from unsloth.chat_templates import get_chat_template, standardize_data_formats
from datasets import load_dataset
tokenizer = get_chat_template(tokenizer, chat_template="gemma-4")
dataset = load_dataset("mlabonne/FineTome-100k", split="train[:3000]")
dataset = standardize_data_formats(dataset)
def formatting_prompts_func(examples):
convos = examples["conversations"]
texts = [
tokenizer.apply_chat_template(
convo, tokenize=False, add_generation_prompt=False
).removeprefix("<bos>")
for convo in convos
]
return {"text": texts}
dataset = dataset.map(formatting_prompts_func, batched=True)FineTome-100k은 고품질 instruction-following 데이터셋이에요. 여기서는 빠른 데모를 위해 3,000개 샘플만 사용했어요. 실전에서는 전체 100k 또는 자체 데이터를 사용하면 돼요. 데이터가 많아지면 학습 시간과 비용도 비례해서 늘어나요 — A100 시간당 $1.55 기준으로 계산하면 돼요.
내 데이터로 학습하고 싶다면, 같은 conversations 포맷으로 JSON 파일을 만들면 돼요:
[
{
"conversations": [
{"from": "human", "value": "질문"},
{"from": "gpt", "value": "답변"}
]
}
]Step 6: 학습 시작
from trl import SFTTrainer, SFTConfig
from unsloth.chat_templates import train_on_responses_only
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=SFTConfig(
dataset_text_field="text",
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
logging_steps=1,
optim="adamw_8bit",
weight_decay=0.001,
lr_scheduler_type="linear",
seed=3407,
report_to="none",
output_dir="/shared/gemma4-finetuned",
),
)
trainer = train_on_responses_only(
trainer,
instruction_part="<|turn>user\n",
response_part="<|turn>model\n",
)
trainer_stats = trainer.train()train_on_responses_only는 모델이 답변 부분만 학습하도록 해요. 질문까지 학습하면 모델이 질문을 따라하는 패턴이 생길 수 있거든요.
체크포인트는 Object Storage(/shared)에 저장되니까, 학습이 중단돼도 이어서 할 수 있어요.
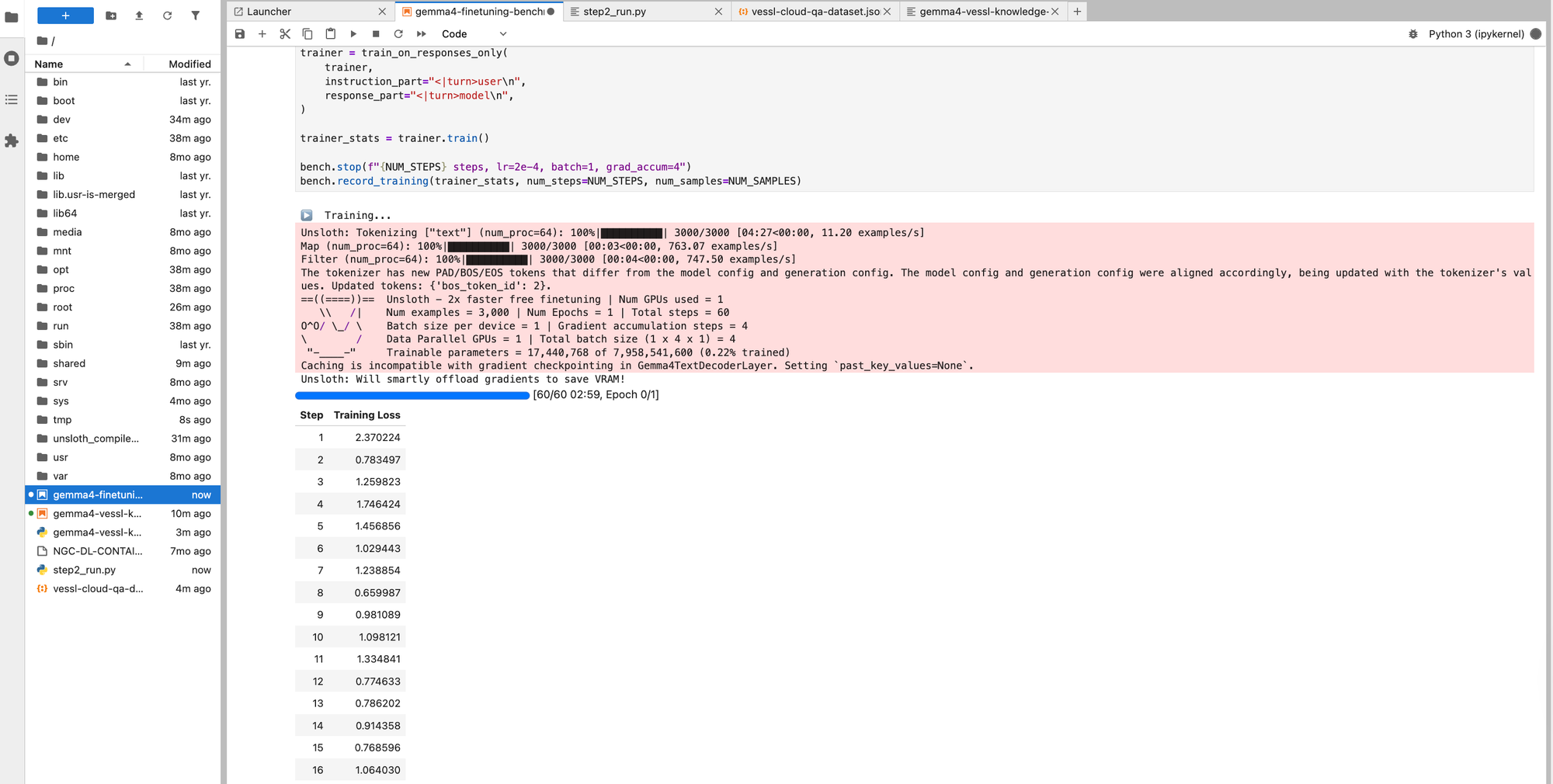
Step 7: 추론 테스트
from transformers import TextStreamer
messages = [
{"role": "user", "content": [
{"type": "text", "text": "Explain quantum computing in simple terms."}
]}
]
_ = model.generate(
**tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to("cuda"),
max_new_tokens=256,
use_cache=True,
temperature=0.7,
streamer=TextStreamer(tokenizer, skip_prompt=True),
)학습 전후 비교
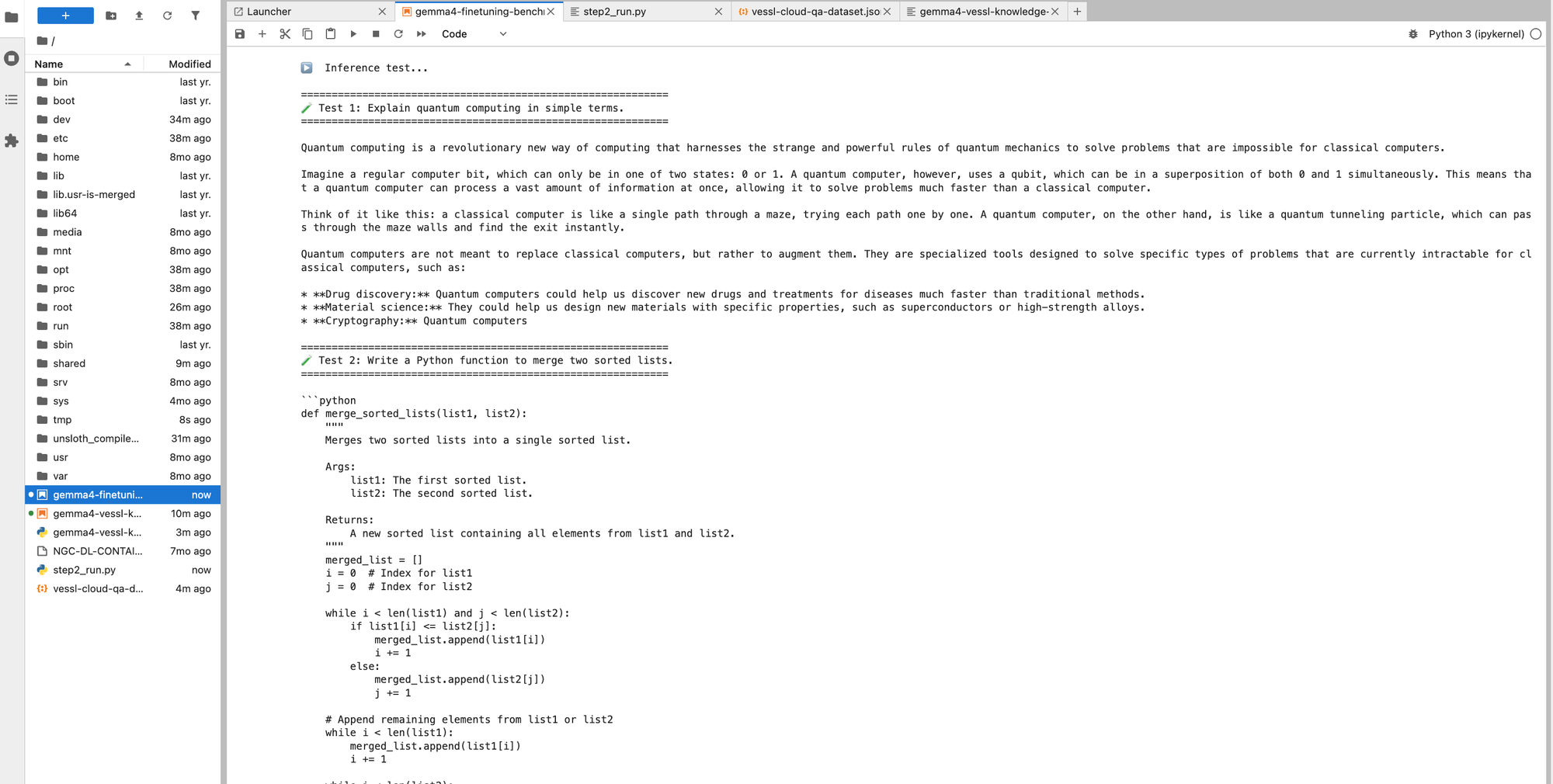
같은 프롬프트를 베이스 모델과 파인튜닝 후 모델에 각각 돌려봤어요. 3,000개 샘플로 8분 학습한 것만으로도 응답 스타일이 확연히 달라져요.
| 프롬프트 | 베이스 모델 | 파인튜닝 후 |
|---|---|---|
| "Explain quantum computing in simple terms." | 이모지와 마크다운 헤딩을 남발하면서 비유 중심으로 설명 (미로 탐험가, 동전 던지기). 장황하고 포맷팅 과다. | 깔끔한 산문체로 개념을 설명한 뒤, 구체적 응용 사례(신약 개발, 소재 과학)까지 자연스럽게 연결. |
| "ML vs deep learning 차이점" | 이모지 헤딩, 장황한 설명이 중간에 끊김. Feature Engineering을 과도하게 강조. | 핵심만 정리하고 비교 테이블을 자발적으로 생성. 한눈에 차이를 파악할 수 있는 구조적 답변. |
| "Palindrome 함수 작성" | 3가지 버전(simple, robust, regex)을 나열하는 오버엔지니어링. 33초 소요. | 딱 한 가지 깔끔한 답변 + 사용 예시. 20.6초에 완료. |
핵심 변화:
- 응답 스타일 — 불필요한 포맷팅(이모지, 과도한 마크다운)이 줄어들고, 간결하고 교과서적인 톤으로 변화
- 정보 구조 — ML/DL 비교에서 비교 테이블을 자발적으로 사용하는 등, 정보 전달 효율이 높아짐
- 코드 답변 — 3가지 버전 나열 → 1가지 핵심 답변 + 실행 예시. 실용적이고 바로 쓸 수 있는 형태
Training Loss가 2.37에서 0.66으로 떨어진 것(72% 감소)이 실제 응답 품질 향상으로 이어진 거예요.
정량적 평가를 하고 싶다면, 학습 데이터에서 테스트 셋을 분리해서 (split="train[:2700]"으로 학습,split="train[2700:3000]"으로 평가) before/after perplexity를 비교하는 방법을 추천해요. 자세한 방법은 쿡북의 Evaluation 섹션을 참고해 주세요.
Step 8: 모델 저장
model.save_pretrained("/shared/gemma4-finetuned/final")
tokenizer.save_pretrained("/shared/gemma4-finetuned/final")Object Storage에 저장했으니까:
- 워크스페이스를 Stop해도 모델이 유지돼요
- 같은 조직의 다른 워크스페이스에서 바로 로딩할 수 있어요
- 팀원이 같은 Object Storage를 마운트하면 모델을 바로 사용할 수 있어요

비용 비교
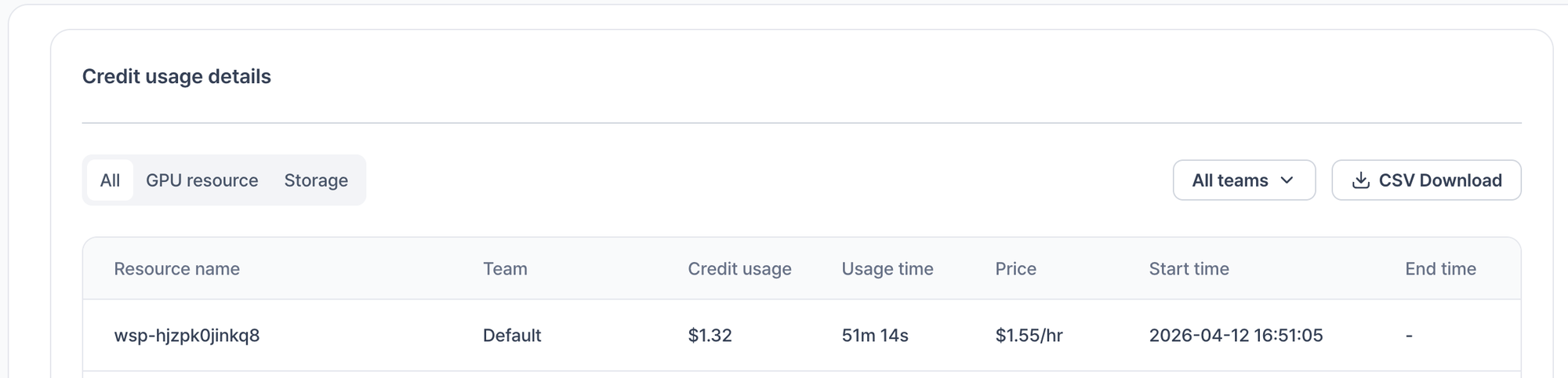
| VESSL Cloud A100 | Colab Pro (A100) | 로컬 (RTX 5090) | |
|---|---|---|---|
| GPU VRAM | 80 GB | 40 GB | 32 GB |
| 이 실험 비용 | $0.38 | ~$0.50 (시간 단위 과금) | 전기세만 |
| 세션 안정성 | 끊김 없음 | 런타임 제한, 연결 끊김 | 안정적 |
| 스토리지 공유 | Object Storage로 팀 공유 | Google Drive | 수동 복사 |
| 대형 모델 (27B+) | H100/A100 선택 가능 | 제한적 | 불가능 |
VESSL Cloud는 초 단위 과금이라 15분 실험에 $0.38만 청구돼요. Colab Pro는 시간 단위라 실제 사용보다 더 과금되는 경우가 많아요.
다음 단계
파인튜닝을 마쳤다면 이런 것들을 시도해볼 수 있어요:
- 내 데이터로 학습: 고객 FAQ, 제품 문서, 도메인 지식으로 전문가 모델 만들기
- DPO/ORPO: 답변 선호도 학습으로 더 자연스러운 응답 만들기
- 더 큰 모델: Gemma 4 27B나 Llama 4 Scout로 스케일업
- GGUF 변환: Ollama나 llama.cpp에서 로컬 추론용으로 변환
FAQ
파인튜닝에 얼마나 걸리나요?
Gemma 4 E4B 기준, A100에서 60 steps 학습이 약 8분이에요. 데이터가 많으면 더 걸리지만, 비례적으로 늘어나요.
GPU를 어떤 걸 골라야 하나요?
Gemma 4 E4B는 A100 SXM 80GB 한 장으로 충분해요 (피크 VRAM 10GB, 80GB 중 12%만 사용). 27B 이상을 파인튜닝할 때도 같은 A100 SXM 80GB에서 4-bit QLoRA로 돌아가지만, 학습 시간을 줄이려면 H100 SXM이 더 나아요. 실시간 가용 SKU는 VESSL Cloud에서 확인할 수 있어요.
워크스페이스를 Stop하면 데이터가 날아가나요?
Cluster Storage와 Object Storage에 저장한 데이터는 유지돼요. 워크스페이스를 Stop하면 GPU 과금이 멈추고, 다시 Start하면 이어서 작업할 수 있어요.
학습 데이터는 어떤 포맷이어야 하나요?
conversations 형식의 JSON이면 돼요. {"from": "human", "value": "..."}, {"from": "gpt", "value": "..."} 쌍으로 구성하면 그대로 사용할 수 있어요.
팀원과 모델을 어떻게 공유하나요?
Object Storage(/shared)에 저장한 모델은 같은 조직 내 다른 워크스페이스에서 바로 마운트해서 사용할 수 있어요. 파일 복사 없이요.
참고 자료
- Google Gemma 4 공식 블로그
- Unsloth Gemma 4 학습 가이드
- FineTome-100k 데이터셋
- VESSL Cloud 가격
- VESSL Cloud
- Gemma 4 파인튜닝 cookbook (GitHub)
이어 읽기


VESSL AI
뉴스레터 구독
AI 인프라 구축 노하우와 최신 GPU 소식을 매달 보내드려요.