NVIDIA B200 GPU 가격·VRAM·스펙 비교 — H100과 무엇이 다를까?

이 글은 VESSL AI 팀이 작성했으며, VESSL Cloud 소개를 포함해요. 스펙 데이터는 NVIDIA 공식 데이터시트 기준이에요. (2026년 4월 기준)
H100 대비 2.3배 이상 성능 | 192GB HBM3e VRAM | 문의 시 확보 가능
NVIDIA B200 GPU는 왜 주목받고 있을까요?
NVIDIA B200은 Blackwell 아키텍처 기반의 데이터센터용 GPU예요. 192GB HBM3e 메모리(클라우드 환경 사용 가능 용량 약 180GB)와 FP4 기준 최대 9,000 TFLOPS 연산 성능을 갖추고 있어요. H100 대비 2배 이상 빠른 연산 능력과 2.4배 큰 VRAM이 특징이에요. 대규모 AI 학습과 추론 모두에서 현시점 가장 현실적인 차세대 GPU예요.
이 글에서는 H100 대비 B200의 가격, 스펙, 클라우드별 제공 현황, 추천 대상을 정리했어요.
H100 다음, 뭘 써야 할까?
H100으로 모델 학습을 돌리는데 시간이 너무 오래 걸리거나, 메모리가 부족해서 모델을 쪼개야 했던 경험이 한 번쯤 있으실 거예요.
AI 모델은 빠르게 커지고 있는데, GPU 선택지는 아직 뚜렷하지 않아요.
H100은 여전히 좋은 GPU예요. 하지만 모델 크기가 커지고, 학습 시간이 길어지고, 추론 요청이 늘어나면서 — 다음 GPU를 찾아보는 팀이 많아졌어요.
그다음 선택지가 바로 NVIDIA B200이에요.
B200은 H100과 뭐가 다른가요?
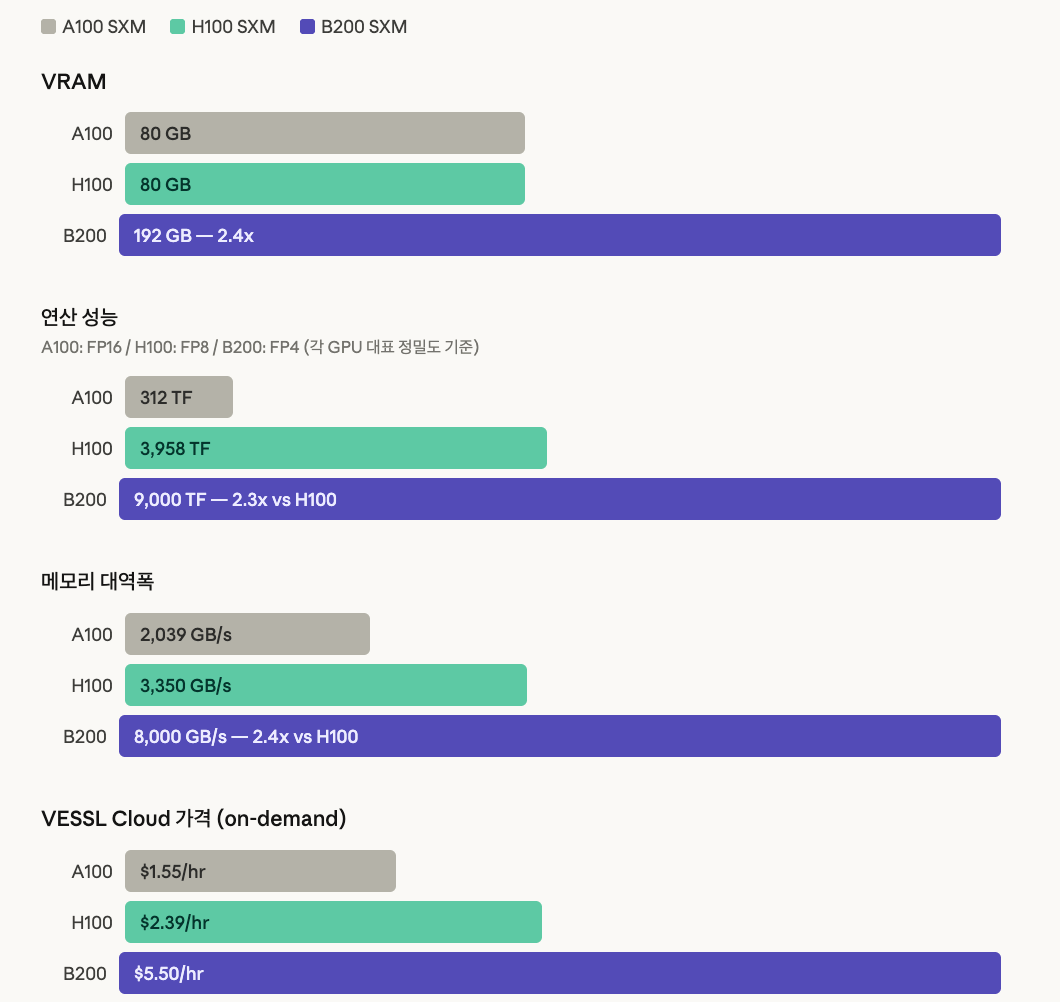
숫자로 비교하면 차이가 명확해요.
연산 성능이 크게 올라갔어요
B200의 FP8 기준 연산 성능은 약 4,500 TFLOPS예요. H100(FP8 약 1,979 TFLOPS, dense 기준) 대비 약 2.3배 수준이에요. FP4 기준으로는 최대 9,000 TFLOPS까지 올라가는데, 이건 H100에는 없는 새로운 정밀도예요. 같은 모델을 학습할 때, 같은 실험을 훨씬 짧은 시간에 끝낼 수 있어요.
VRAM이 2.4배
B200은 192GB HBM3e 메모리를 탑재했어요. H100(80GB)의 2.4배예요. 70B 파라미터 모델도 별도 파티셔닝 없이 단일 GPU에서 추론이 가능해요. H100에서는 2장으로 나눠야 했던 작업이 1장으로 해결돼요.
추론 처리량이 크게 올라갔어요
Blackwell 아키텍처에 새로 도입된 FP4 Transformer Engine 덕분에, LLM 추론 성능이 이전 세대 대비 크게 향상됐어요. 토큰당 비용을 낮추면서 서빙 품질을 유지할 수 있어요.
메모리 대역폭도 2배
B200의 메모리 대역폭은 8,000 GB/s로, H100(3,350 GB/s)의 약 2.4배예요. VRAM 용량만큼 중요한 건 데이터를 얼마나 빠르게 읽어오느냐인데, 대규모 모델에선 이런 대역폭 차이가 데이터 전송 병목을 줄이고 실제 처리량 향상으로 이어질 수 있어요.
전력 효율도 개선됐어요
B200의 TDP는 1,000W예요. 성능 대비 와트당 효율(perf/watt)이 H100 대비 개선됐어요. 같은 전력으로 더 많은 연산을 처리할 수 있어요.
B200 GPU 스펙 비교표
| GPU | VRAM | 연산 성능 | 메모리 대역폭 | VESSL Cloud 가격 | 추천 상황 |
|---|---|---|---|---|---|
| A100 SXM | 80GB | 312 TFLOPS (FP16) | 2,039 GB/s | $1.55/hr | 비용 효율이 최우선인 팀 |
| H100 SXM | 80GB | 3,958 TFLOPS (FP8) | 3,350 GB/s | $2.39/hr | 대형 워크로드, 검증된 환경 |
| B200 SXM | 192GB | 9,000 TFLOPS (FP4) | 8,000 GB/s | $5.50/hr | H100에서 업그레이드가 필요한 팀 |
| GB200 | 시스템 단위 | NVLink 최적화 | — | 세일즈 상담 | 초대규모 분산 학습 |
| B300 | 288GB | ~14,000 TFLOPS (FP4) | — | $7.50/hr | 최대 성능이 필요한 팀 |
가격은 VESSL Cloud on-demand 기준이며, 시점에 따라 변동될 수 있어요. 최신 가격은 vessl.ai/pricing에서 확인해 주세요. 스펙은 NVIDIA 공식 데이터시트 기준이에요. 연산 성능은 각 GPU의 대표 정밀도(precision) 기준으로, 정밀도가 다르기 때문에 단순 수치 비교에는 주의가 필요해요.
다른 클라우드와 비교하면 어떤가요?
B200을 어디서 쓰느냐에 따라 비용 차이가 커요. 같은 GPU라도 프로바이더마다 가격이 다르거든요.
| 프로바이더 | B200 On-demand 가격 (GPU 당) | 기준일 |
|---|---|---|
| VESSL Cloud | $5.50/hr | 2026년 4월 |
| Lambda Labs (8x 인스턴스) | $6.69/hr | 2026년 4월 |
| Lambda Labs (1x 인스턴스) | $6.99/hr | 2026년 4월 |
| AWS p6-b200.48xlarge | ~$14.24/hr (GPU 당 환산) | 2026년 4월 |
AWS 대비 약 60% 이상 절감돼요. 출처: AWS 공식 pricing, Lambda Labs 공식 pricing (2026년 4월 기준). 프로바이더별 부가 비용(네트워크, 스토리지 등)은 포함되지 않은 GPU 단가 비교예요.
어떤 팀에 B200이 맞을까?
모든 팀이 최신 GPU가 필요한 건 아니에요. B200이 특히 효과적인 경우는:
- H100으로 학습 시간이 너무 긴 팀 — 같은 실험을 절반 가까이 단축할 수 있어요
- 모델 크기가 커서 메모리가 부족한 팀 — 192GB VRAM으로 파티셔닝 부담이 크게 줄어요
- 추론 서빙 비용을 줄이고 싶은 팀 — 처리량이 늘어나면서 토큰당 비용이 낮아져요
- H100 → 다음 세대로 넘어가는 타이밍을 보는 팀 — B200이 가장 현실적인 업그레이드 경로예요
반대로, 현재 H100으로 워크로드가 충분하거나 비용 효율이 최우선이라면 A100/H100이 여전히 좋은 선택이에요.
직접 구매와 클라우드, 뭐가 다른가요?
B200을 직접 구매하려면 리드타임이 길어요. Blackwell 시리즈는 전 세계적으로 수요가 공급을 초과하고 있어서, 일반 기업의 직접 구매 리드타임은 12개월 이상이에요.
GPU만 확보한다고 끝나는 것도 아니에요. 전력, 냉각, 랙, 네트워크 인프라까지 갖춰야 해서 초기 투자가 크고요. B200은 GPU 하나당 TDP가 1,000W라서, 전력과 냉각 설계부터 신경 쓸 게 많아요.
GPU 클라우드를 쓰면 이 과정을 건너뛸 수 있어요. 필요한 만큼, 필요한 시점에, 바로 시작할 수 있어요.
VESSL Cloud에서 B200 쓰기
VESSL Cloud에서는 B200을 포함해 A100, H100, GB200, B300까지 — 워크로드에 맞는 GPU를 문의를 통해 확보할 수 있어요.
AWS 대비 약 60% 이상 비용 절감
같은 B200을 AWS에서 쓸 때와 비교하면, VESSL Cloud의 GPU 단가는 약 60% 이상 저렴해요. AI 전용 인프라를 직접 운영하기 때문에 가능한 구조예요.
Smart Pausing — 안 쓰는 시간에는 자동으로 멈춰요
고성능 GPU일수록 유휴 비용이 커요. VESSL Cloud는 사용하지 않는 시간에 워크스페이스를 자동으로 멈춰서 체감 비용을 크게 줄여줘요. 분 단위 과금이라 짧은 실험도 부담 없어요.
유연한 스케일링
실험 단계에서는 작게 시작하고, 학습 구간에서만 스펙을 올렸다가, 다시 내릴 수 있어요. Pause 후 재시작해도 환경이 그대로 유지돼요.
구성까지 함께 설계
GPU 선택만으로 끝나지 않잖아요. 멀티 노드, InfiniBand, 스토리지 조건까지 워크로드에 맞춰서 함께 제안 드려요.
자주 묻는 질문 (FAQ)
B200 GPU는 어떤 워크로드에 적합한가요?
대규모 LLM 학습(70B+ 파라미터), 대형 모델 추론 서빙, 메모리가 많이 필요한 멀티모달 학습에 적합해요. H100에서 메모리나 성능 병목을 느끼는 팀이라면 B200이 효과적이에요.
B200과 H100의 가장 큰 차이점은 뭔가요?
VRAM이 80GB → 192GB로 2.4배 늘어났고, 연산 성능은 약 2.3배 향상됐어요. 메모리 대역폭도 2배 이상이에요. 큰 모델을 다루는 팀에게 가장 체감이 큰 차이는 VRAM이에요. 70B 모델을 H100에서는 2장으로 나눠야 했다면, B200에서는 1장으로 충분해요.
B200 GPU를 클라우드로 쓸 수 있나요?
아직 바로 쓸 수는 없습니다. 영업팀 문의를 통해서 미리 선점할 수 있어요.
B200 GPU 클라우드 가격은 얼마인가요?
VESSL Cloud 기준 on-demand $5.50/hr예요. AWS p6-b200.48xlarge는 GPU 당 환산 약 $14.24/hr이고, Lambda Labs 인스턴스는 $6.69~$6.99/hr 수준이에요. (2026년 4월 기준, 변동 가능)
B200과 B300의 차이는 뭔가요?
B300은 Blackwell Ultra 아키텍처로, VRAM이 288GB로 B200(192GB)보다 크고 FP4 연산 성능도 약 14,000 TFLOPS로 55% 이상 높아요. 다만 가격도 더 높고, 아직 공급이 제한적이에요. 대부분의 팀에게는 B200이 성능과 비용의 균형이 가장 좋은 선택이에요.
VESSL Cloud에서 워크로드에 맞는 GPU 구성을 확인해 보세요.
더 자세한 구성 상담이 필요하다면 영업팀에 문의해 주세요.
VESSL AI
뉴스레터 구독
AI 인프라 구축 노하우와 최신 GPU 소식을 매달 보내드려요.