GPU 크레딧 샐 걱정 없게. 당신을 위한 구원투수 — Job

잠든 사이에 크레딧이 빠져나가던 경험, 한 번쯤 있으시죠?
A100이 필요해서 워크스페이스를 start 해두고 잠들었어요. 큐에 밀려 있다가 새벽에 자원이 할당됐고, 학습은 30분 만에 끝났어요. 그런데 아침에 보니 워크스페이스는 여전히 돌아가고 있었고, 크레딧은 네 시간어치가 빠져나가 있었어요.
이런 경험, 낯설지 않으시죠?
- 내가 잠든 사이에 GPU가 할당받아져서 불필요한 크레딧이 차감된 경험
- 원하는 만큼만 GPU를 쓰고 싶은데 언제 시작할지 몰라 기다리기만 하던 경험
- 학습은 끝났는데 워크스페이스를 안 꺼서 빈 GPU에 돈을 낸 경험
- 하이퍼파라미터 여러 개를 한 번에 돌리고 싶은데 워크스페이스 여러 개를 수동으로 관리하기 벅찼던 경험
Job은 이걸 해결해요. 스크립트를 제출하면 VESSL Cloud가 알아서 GPU를 할당하고, 학습이 끝나는 순간 자원을 반납해요.
Workspace vs Job — 언제 뭘 쓰면 될까요?
| Workspace | Job | |
|---|---|---|
| 목적 | 인터랙티브 개발 & 디버깅 | 자동화된 학습 & 배치 처리 |
| 접근 방식 | SSH, Jupyter, VS Code 접속 | 스크립트 제출 → 로그 확인 |
| 라이프사이클 | 직접 시작/중지/삭제 | 실행 완료 시 자동 종료 |
| 과금 | 실행 중인 시간 전체 | 실제 사용 시간만 |
요약하면: 코드를 짜고 중간 결과를 바로 확인하면서 탐색할 때는 Workspace가 편해요. 셀 단위로 돌려보고, 환경을 유지한 채 다음 실험으로 넘어갈 수 있으니까요. 반대로, 검증된 코드를 큐에 던져놓고 끝날 때 알아서 종료되는 기능이 필요할 땐 Job이 나아요.
30초 설치
아래 시나리오를 돌려보기 전에 vesslctl을 설치하고 로그인해요.
1. vesslctl 설치
curl -fsSL https://api.cloud.vessl.ai/cli/install.sh | bash2. 로그인
vesslctl auth login브라우저 OAuth로 로그인만 하면, 아래 시나리오 어떤 거든 바로 제출할 수 있어요.
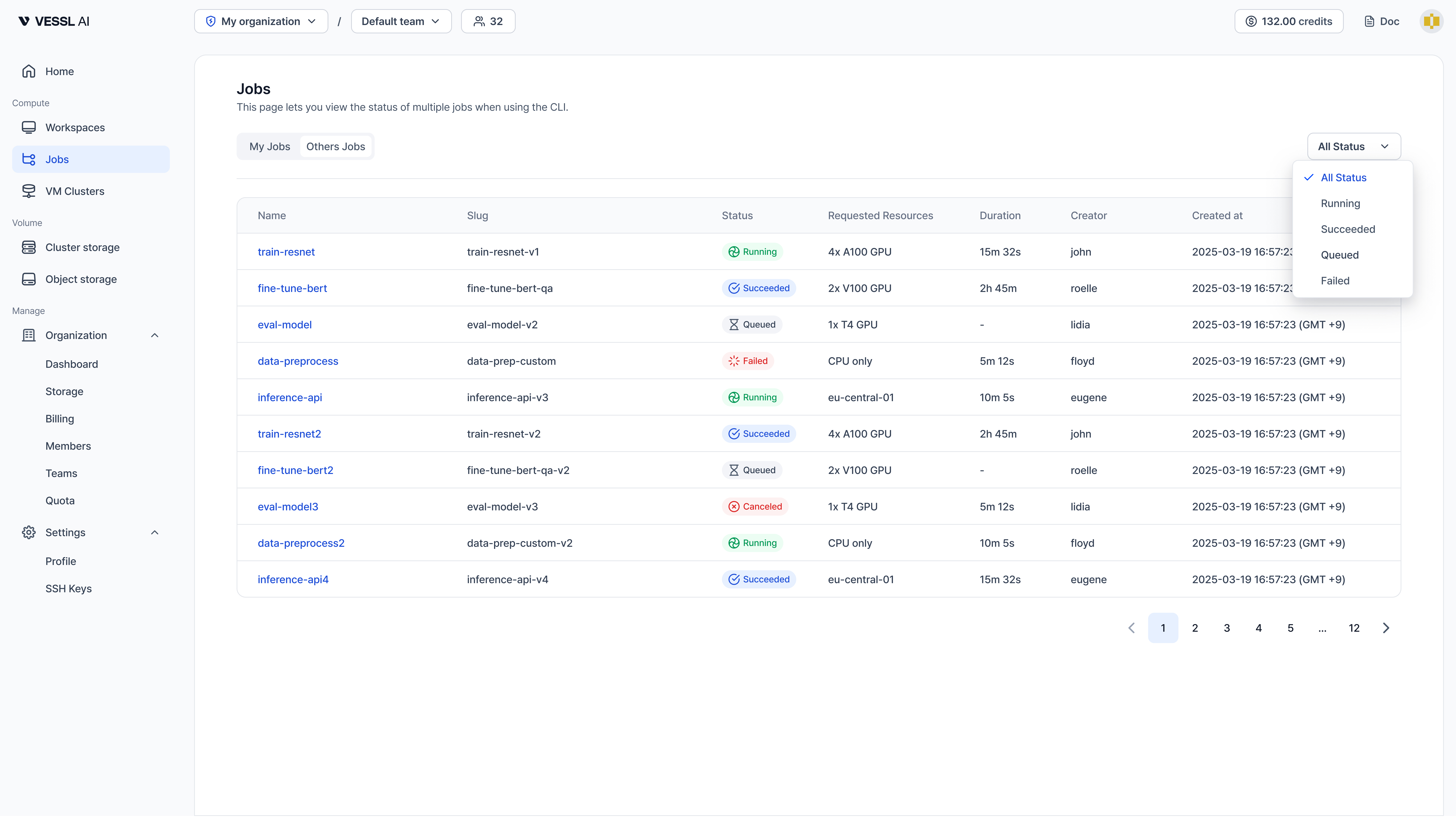
크레딧 확인하기
로그인이 끝나면vesslctl billing show로 조직의 크레딧 잔액을 확인해 주세요. 잔액이 0이면workspace create와job create가 실행 직전에 차단돼요. 부족하면 VESSL Cloud에서 먼저 충전할 수 있어요.
리소스 스펙, 볼륨 slug 찾기
아래 시나리오의<your-resource-spec-slug>는vesslctl resource-spec list로,<your-volume-id>는vesslctl volume ls로 본인 조직에서 확인할 수 있어요.
이런 상황에서 Job을 써보세요
1. 제출하고 자러 가고 싶은 간단한 학습
학습 코드가 준비됐고, GPU 한 장에서 몇 시간 돌리면 되는 경우예요. Workspace로 돌리면 끝나고 나서 수동으로 꺼줘야 하는데, 그러다 보면 "아 이거 끝나면 내가 꺼야 하는데..." 하고 계속 들여다보게 되잖아요.
vesslctl job create \
--resource-spec <your-resource-spec-slug> \
--image "pytorch/pytorch:2.3.0-cuda12.1-cudnn8-runtime" \
--cmd "python train.py --epochs 50 --batch-size 128"A100 SXM 기준 시간당 $1.55, 학습이 끝나는 순간 자원이 반납되고 과금도 같이 멈춰요.
2. 여러 조합을 한 번에 작업하고 싶을 때
learning rate 3개 × batch size 3개 = 9가지 조합을 한 번에 돌려보고 싶을 때요.
Workspace로도 할 수는 있어요. 각 조합마다 하나씩 띄워 돌리는 거죠. 다만 start 버튼을 아홉 번 누르고, 끝났는지 주기적으로 들여다보고, 끝난 건 수동으로 꺼야 해요. 하나라도 깜빡하면 빈 GPU에 밤새 돈이 나가요. Workspace는 한 실험에 붙어서 셀을 바꿔가며 탐색하는 작업엔 잘 맞지만, 9개를 병렬로 던져놓고 끝나면 알아서 종료되는 류의 작업은 Job에 맡기는 게 편해요.
for lr in 1e-3 3e-4 1e-4; do
for bs in 32 64 128; do
vesslctl job create \
--resource-spec <your-resource-spec-slug> \
--image "pytorch/pytorch:2.3.0-cuda12.1-cudnn8-runtime" \
--cmd "python train.py --lr $lr --batch-size $bs" \
--name "sweep-lr${lr}-bs${bs}"
done
done9개 Job이 동시에 실행돼요. 각각 독립적으로 자원을 할당받고, 끝난 순서대로 반납해요. 어떤 게 먼저 끝나든 어떤 게 실패하든 신경 쓰지 않아도 돼요. 전부 알아서 정리되니까요.
9개는 이 예시의 숫자일 뿐이에요. 반복문 범위만 넓히면 25개도, 125개도 같은 패턴으로 돌아가요. Job 자체에는 동시 실행 개수 제한이 없고, 조직 GPU 가용 자원이 실질적인 상한이에요.
3. 밤새 돌리고 아침에 결과만 보고 싶을 때
큰 모델은 몇 시간, 길게는 하루씩 걸리죠. 자는 동안 뭔가 잘못돼서 처음부터 다시 돌리는 상상을 하면 불안해서 닫기 전에 10분마다 로그 확인하게 되잖아요. Job은 실패해도 자동 종료되니까 과금이 이어지지 않고, 체크포인트를 Object Storage에 저장해두면 마지막 지점부터 이어서 시작할 수 있어요. 아침에 일어나서 성공/실패 메시지만 확인하면 돼요.
vesslctl job create \
--resource-spec <your-resource-spec-slug> \
--image "pytorch/pytorch:2.3.0-cuda12.1-cudnn8-runtime" \
--object-volume "my-checkpoints:/mnt/checkpoints" \
--cmd "python train.py \
--epochs 200 \
--checkpoint-dir /mnt/checkpoints \
--save-every 10"H100은 A100보다 시간당 단가(시간당 $2.39)가 높지만, FP8 지원과 넓은 메모리 대역폭 덕분에 긴 학습은 오히려 총 비용이 낮아지는 경우가 많아요. 야간 학습처럼 작업이 길어질수록 차이가 커져요.
4. 실전 예시 — Gemma 4 파인튜닝
위 네 가지는 형태예요. 실제로 돌려본 워크플로우를 하나 풀어드릴게요. Gemma 4 E4B를 Job 다섯 개로 파인튜닝하고, 같은 인프라에서 베이스 모델, 일반 데이터 학습 모델, VESSL Cloud 도메인 학습 모델을 비교했어요.
Object storage 볼륨 하나에 스크립트와 데이터셋을 올려두고, 모든 Job이 /shared에 마운트해요. 데이터셋은 환경변수 하나로 분기해요. 스크립트 전문(finetune_gemma4.py)과 submit.sh 래퍼는 Gemma 4 파인튜닝 cookbook에서 그대로 받을 수 있어요.
# 한 번만 업로드 — 스크립트 + 데이터셋
vesslctl volume upload <your-volume-id> finetune_gemma4.py --remote-prefix scripts/
vesslctl volume upload <your-volume-id> vessl-cloud-qa-dataset.json --remote-prefix datasets/
# 일반 데이터 Job
vesslctl job create \
--name gemma4-generic \
--resource-spec <your-resource-spec-slug> \
--image pytorch/pytorch:2.5.1-cuda12.4-cudnn9-devel \
--object-volume <your-volume-id>:/shared \
--env DATASET_MODE=generic \
--cmd "pip install unsloth trl transformers datasets && python -u /shared/scripts/finetune_gemma4.py"
# VESSL 도메인 Job(DATASET_MODE만 바꿔서 제출)
vesslctl job create \
--name gemma4-vessl \
--resource-spec <your-resource-spec-slug> \
--image pytorch/pytorch:2.5.1-cuda12.4-cudnn9-devel \
--object-volume <your-volume-id>:/shared \
--env DATASET_MODE=vessl \
--cmd "pip install unsloth trl transformers datasets && python -u /shared/scripts/finetune_gemma4.py"
# 로스 커브 실시간 확인, 최종 상태와 비용 조회
vesslctl job logs <slug> --follow
vesslctl job show <slug>
vesslctl billing show다섯 번 돌려서 강한 결과 두 개를 비교해보면:
| Job | 데이터셋 | 학습 시간 | Final loss | 비용 |
|---|---|---|---|---|
| Generic | FineTome-100k (3,000개) | 15분 44초 | 4.06 | $0.41 |
| VESSL-domain | VESSL QA (36개, 20 에폭, r=32) | 22분 12초 | 0.61 | $0.57 |
"VESSL Cloud 워크스페이스를 일시 중지해서 비용을 아끼려면 어떻게 해야 하나요?"라고 물었을 때, 베이스 모델과 일반 데이터 학습 모델은 둘 다 "해당 문서를 찾을 수 없어요…"라고 거절했어요.
VESSL Cloud 도메인으로 학습한 모델은 "VESSL Cloud의 Pause 기능을 사용하세요. CPU와 메모리 사용이 즉시 중단돼요…"라고 답했어요. 올바른 도메인 데이터 36개가, 일반 대화 데이터 3,000개로는 바꾸지 못한 응답 패턴을 바꿨어요.
Job이 완료되거나 실패하면 자동으로 종료되니까, 실패해도 돈이 새진 않아요. 다섯 번 전체, 총 $1.72예요. 참고로 하이퍼스케일러의 8-GPU 인스턴스(시간당 약 $22) 기준으로 같은 실험 다섯 번을 돌렸다면 3분만 Idle 상태여도 약 $10가 날아가요.

같은 실험을 JupyterLab 워크스페이스에서 실행해본 블로그 글이에요.
FAQ
Job이 실패하면 어떻게 되나요?
Job이 비정상 종료되면 상태가 failed로 표시돼요. vesslctl job logs로 에러 로그를 확인하고, 수정 후 다시 제출하면 돼요. Object Storage에 체크포인트를 저장해 두었다면, 마지막 체크포인트부터 이어서 학습할 수 있어요.
Workspace에서 Job을 제출할 수 있나요?
네, Workspace 터미널에서 vesslctl job create 명령어를 실행하면 돼요. 코드를 Workspace에서 개발하고 디버깅한 다음, 검증이 끝나면 바로 Job으로 제출하는 워크플로우를 추천해요.
Job 간에 데이터를 어떻게 전달하나요?
Object Storage를 사용하면 돼요. 여러 Job에 같은 Object Storage 볼륨을 마운트하면, 한 Job의 출력을 다음 Job의 입력으로 사용할 수 있어요. 위의 CPU→GPU 파이프라인 예시처럼요.
Job 스크립트를 미리 세팅해두고 재활용할 수 있나요?
네. vesslctl job create 명령어를 셸 스크립트나 Makefile에 담아두면 같은 설정을 몇 번이고 재사용할 수 있어요. 리소스 스펙, 이미지, 명령어, 볼륨을 한 번만 정의해두면 make train 한 줄로 제출할 수 있고, 팀원과 공유하기도 편해요. 인터랙티브 탐색은 Workspace에서 하다가, 검증된 파이프라인은 스크립트로 굳혀 Job으로 반복 제출하는 흐름을 추천해요.
References
- VESSL Cloud Job 문서
- vesslctl CLI 설치 가이드
- GPU 가격표 — A100 SXM $1.55/hr, H100 SXM $2.39/hr, L40S $1.80/hr
이어 읽기
VESSL AI