H100 8장 & Qwen3.5-35B로 금융 LLM 만들기: Full-weight 레시피

TL;DR
트레이딩 회사가 미래 정보 누수(Lookahead bias)를 통제한 금융 LLM을 만들려면, 최소한 H100 8장과 35B 베이스 모델이 필요해요. 이 글에서는 그 환경을 어떻게 세팅했는지 공유해요. Qwen3.5-35B-A3B-Base 모델에 특정 시점 기준의 데이터 10억 토큰을 추가 사전학습(Continued pretraining)했고, 누수 프리미엄(Leakage premium)이 통계적으로 줄었는지 R²(결정계수)로 측정했어요.
본문은 크게 세 가지를 다뤄요. (1) 누수 측정 방법과 결과, (2) 이 누수가 사전 학습 때문인지 확인한 통제 실험, (3) 단일 GPU에서 LoRA로 학습한 결과와의 비교예요. 마지막 부록에서는 (4) 왜 H100 한 장으로는 부족한지, 그리고 H100 8장으로 35B 전체 학습을 성공하기까지 겪은 4번의 트러블슈팅 과정을 정리했어요.
이 실험은 Bryan Kelly 연구진의 시점 기준 언어 모델(point-in-time language model) 연구에서 영감을 받아, 상용 35B 베이스에 적용해 본 거예요.
EN: Building a point-in-time finance LLM on 8×H100 + Qwen3.5-35B
실험 쿡북: 멀티GPU 쿡북
금융 예측 LLM이 넘어야 할 산
최근 로빈후드(Robinhood)가 고객을 위한 "에이전틱 트레이딩(Agentic Trading)" 플랫폼을 열었어요. 누구나 AI 에이전트에게 투자를 맡길 수 있게 되면서 AI 기반 트레이딩이 빠르게 대중화되고 있죠. 그리고 최상위 트레이딩 회사들의 베팅 규모도 어마어마해요. 점프 트레이딩(Jump Trading)은 이번 GTC 타이베이(Taipei)에서 NVIDIA의 차세대 플랫폼 Vera Rubin(NVL144)을 가장 먼저 도입하겠다고 밝혔고, 제인 스트리트(Jane Street)는 CoreWeave에 60억 달러를 약정하며 AI 클라우드 물량을 확보했어요.
에이전틱 트레이딩이 보편화될수록, 트레이딩 회사는 각자의 고유한 전략에 맞춰 독자적인 모델 성능을 끌어올려야만 알파(Alpha)를 확보할 수 있는 시대가 왔어요. 하지만 상용 오픈소스 LLM을 그대로 가져다 쓰기엔 큰 문제가 하나 있어요. 바로 데이터 학습 시점이에요.
대부분의 오픈소스 LLM은 인터넷 전체 데이터를 한 번에 모아 학습해요. 그래서 모델에 "2017년 기준으로 2018년 주가 수익을 예측해 줘"라고 하면 문제가 생기죠. 겉보기엔 2017년 기준 같지만, 사실 모델은 이미 2018년의 기사나 리포트를 학습한 상태일 수 있거든요. 이를 학계에서는 미래 정보 누수(Lookahead bias)라고 불러요. 과거엔 알 수 없던 힌트가 모델에 남아 예측에 영향을 주는 현상이에요.
이런 모델을 쓰면 트레이딩 회사 입장에서는 백테스트(Backtest)의 신뢰도가 흔들릴 수밖에 없어요. 테스트 결과가 진짜 알파를 발생시킨건지, 아니면 모델이 미래 데이터를 미리 학습해서 생긴 착시인지 구분하기 어려워지니까요.
이 문제를 해결하기 위해 AQR 캐피털(AQR Capital Management)의 머신러닝 헤드이자 예일대 교수인 브라이언 켈리(Bryan Kelly) 연구진은 데이터를 시간순으로 잘라 각 시점까지 공개된 텍스트만 학습하는 4B 파라미터 모델을 만들었어요. 하지만 트레이딩 회사가 현업에서 쓰는 30B~70B급 모델에 적용하려면 더 큰 스케일의 레시피가 필요하죠.
이 글에서는 상용 수준의 35B 모델에 시점 기준 학습을 적용하는 방법과, 그 결과가 통계적으로 유의미한지 확인하는 측정 도구를 정리했어요.
측정 도구: 두 R²의 차이
핵심은 하나의 모델을 두 가지 방식으로 평가하는 거예요. 평가할 때 Kaggle JPX(일본 거래소 주가 예측 대회) 데이터를 활용해 점수 차이를 비교했어요.
- 미래 정보 차단 평가(R² leakage-off): 시간을 엄격하게 지킨 평가예요. 2020년 12월 31일 이전은 학습(Train), 2021년 1월 1일 이후는 평가(Test)로 나눠 미래 정보가 새지 않게 했어요. 실제 과거 기준의 예측 성능과 가장 가까워요(시간순 분할(Chronological split)).
- 미래 정보 누수 평가(R² leakage-on): 종목은 겹치지 않게 분리되어 있지만(Disjoint), 데이터의 시점 섞임(Temporal Mixing)이 일어나도록 의도적으로 설계한 정보 누수 발생(Leakage-prone) 평가 조건인 그룹 K-폴드(GroupKFold)예요. 평가 프로토콜 내 시점 섞임 현상이 R²를 얼마나 부풀리는지 측정하기 위해 사용했어요.
- 누수 프리미엄(Leakage premium = r2_on − r2_off): 정보 누수 발생 평가가 점수를 얼마나 부풀렸는지 보여주는 값이에요.
비교 대상은 두 가지예요. 하나는 학습하지 않은 Qwen3.5-35B-A3B-Base 모델이고, 다른 하나는 이 모델에 특정 시점 기준의 데이터 10억 토큰을 추가 사전학습한 모델이에요. 두 모델의 누수 프리미엄을 각각 구한 뒤, 학습 전 누수 프리미엄에서 학습 후 누수 프리미엄을 빼서(Premium Reduction) 누수가 얼마나 줄었는지 확인했어요.
이 실험의 가설은 이래요. 시점 기준 데이터 10억 토큰을 추가 사전학습하면, 프리미엄 감소폭이 0보다 커질 것이다.
통계적 유의성은 클러스터 부트스트랩(Clustered bootstrap)으로 검증했어요. 1,000개의 종목에서 200번 표본을 다시 뽑아 결과의 변동성을 확인했죠. 만약 95% 신뢰구간(CI)에 0이 포함된다면, "프리미엄 감소가 통계적으로 유의하지 않다"는 뜻이에요.
레시피 상세
H100 8장으로 세팅한 레시피는 다음과 같아요.
| 항목 | 값 |
|---|---|
| 베이스 모델 | Qwen/Qwen3.5-35B-A3B-Base (35B 전체, 토큰당 약 3B가 활성화되는 MoE 구조) |
| 데이터 | HuggingFaceFW/fineweb, CC-MAIN ≤ 2017-06-30 덤프 (10억 토큰) |
| 학습 토큰 수 | 10억(1B) 토큰 |
| 학습 방식 | 전체 추가 사전학습 (Full-weight continued pretraining. 35B 파라미터 전체 학습) |
| 분산 학습 | axolotl 0.16 + FSDP2 + Activation checkpointing 끔 |
| 옵티마이저 | adamw_torch_fused (GPU에서 빠르게 동작하는 PyTorch 기본 AdamW) |
| 정밀도 | bf16 |
| GPU | 8×H100 SXM (NVLink로 연결된 단일 서버) |
| 학습 시간 | 18시간 36분 (실제 트레인 런타임(train_runtime) 실측 기준) |
| 학습 비용 | 약 378달러 (평가 포함 총 ~$386) |
| 평가 | Kaggle JPX, 1,000개 종목, 테스트 표본 5,817개, 200번 부트스트랩 |
MoE(전문가 혼합, Mixture of Experts) 구조 덕분에 모델 전체 크기는 35B지만, 토큰 1개를 처리할 때 실제로는 약 3B만 활성화돼요.
이 설정으로 18시간 36분 동안 56,430 스텝(에폭(Epoch) 1.0)을 학습했고, 최종 학습 손실(Train loss)은 2.182를 기록했어요. 학습이 끝난 가중치는 VESSL Cloud의 오브젝트 스토리지(Object storage)에 저장했어요. 단일 H100으로 학습할 수 없는 이유와 최적의 설정값을 찾은 과정은 글 하단 부록에 남겨두었어요.
측정 결과
평가는 기존 LoRA 쿡북의 도구를 그대로 활용했어요. (1,000 종목 × 30개 시점, 테스트 표본 약 5,817개, 200번 부트스트랩) 평가에 걸린 시간은 약 2시간 50분이었고, 학습과 평가를 합친 총비용은 약 386달러였어요.
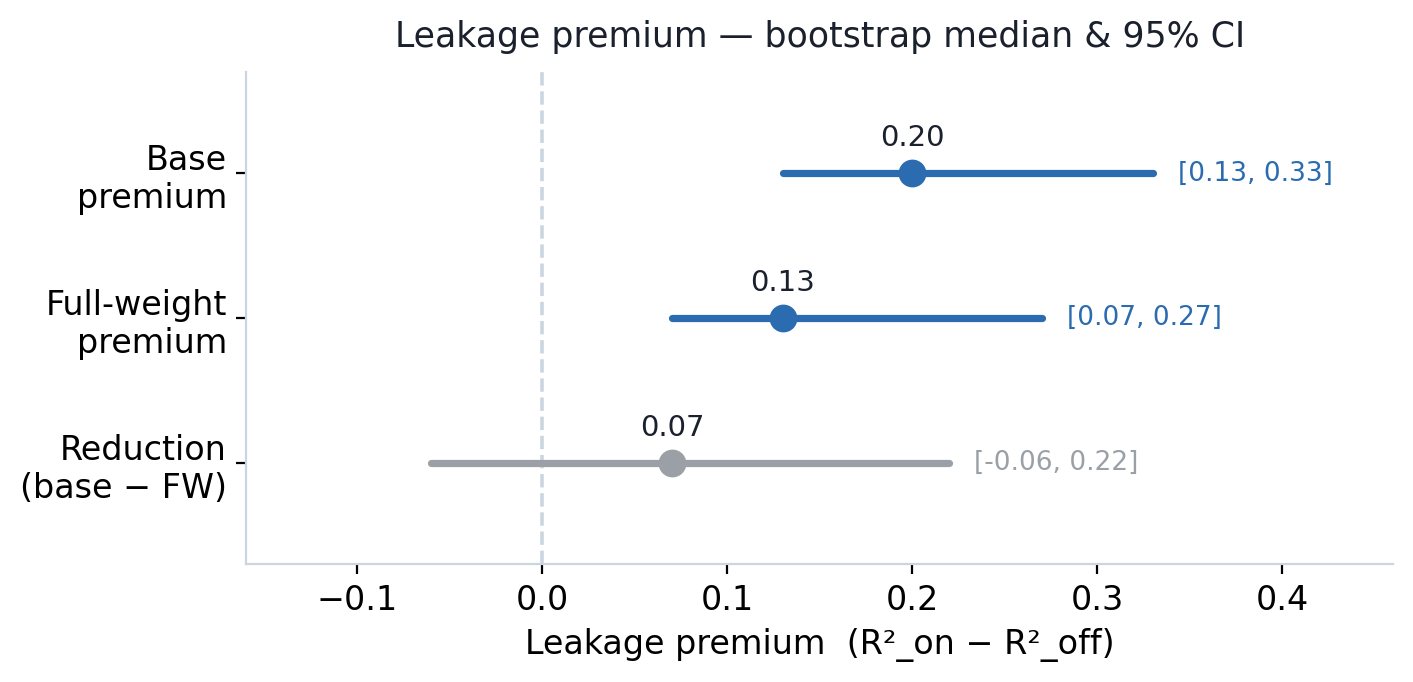
| 지표 | Base(학습 전 베이스) | 전체 학습(이번 실험) |
|---|---|---|
| r2_leakage_off(미래 정보 차단 평가) | −0.1936 | −0.1577 |
| r2_leakage_on(미래 정보 누수 평가) | −0.0562 | −0.0678 |
| Leakage premium = 중앙값 [95% CI] | 0.20 [0.13, 0.33] | 0.13 [0.07, 0.27] |
| Premium reduction = 중앙값 [95% CI] | (기준) | 0.07 [−0.06, 0.22] |
결과를 해석하는 방법은 간단해요. 95% 신뢰구간(CI)에 0이 없다면 통계적으로 의미 있게 감소했다는 뜻이고, 0이 포함된다면 "방향성은 맞지만 통계적으로 유의하지 않다"는 의미예요.
트레이딩 회사 입장에서는 다음 세 가지 인사이트를 얻을 수 있어요.
- 신뢰구간이 0을 배제할 때: 10억 토큰 학습으로 누수가 줄었다는 통계적 증거와 일치해요. H100 8장과 35B 모델의 조합이 누수 문제를 해결할 수 있음을 의미해요.
- 신뢰구간에 0이 포함될 때: 현재 세팅(10억 토큰 / 1,000개 종목)만으로는 누수 프리미엄이 유의미하게 줄었다고 말하기 어려워요(유의하지 않음). 학습 토큰 수를 늘리거나 평가 방식을 수정해 신뢰구간을 더 좁혀야 해요.
- R² 자체가 음수일 때:
r2_leakage_on조건에서도 베이스와 학습 후 모두 음수를 기록했어요. 누수(Leakage)가 모델을 다운스트림 태스크에서 "이기게(Win)" 만든 게 아니라, 단지 "덜 틀리게" 만들었을 뿐임을 보여줘요.
📊 이번 실험 결과는 두 번째 시나리오에 가까웠어요. 누수 감소폭의 중앙값은 +0.07로 방향은 맞았지만, 신뢰구간에 0이 포함됐어요. 즉, 10억 토큰 학습만으로는 누수 프리미엄 감소가 통계적으로 유의하지 않아요. 다만 학습 전후의 누수 프리미엄 자체는 모두 신뢰구간이 0을 벗어났기 때문에, 미래 정보 누수가 평가 점수를 부풀린다는 점은 확실해요.
누수의 채널 분리와 통제 실험
우리가 측정한 누수 프리미엄이 "모델이 사전 학습 때 미래 데이터를 미리 학습해서(Pretraining 오염)" 생긴 걸까요? 아니면 "평가 방식인 그룹 K-폴드의 시점 섞임" 때문일까요? 두 채널을 분리하기 위해 지식 마감 시점(Knowledge Cutoff)이 다른 ChronoGPT 모델들로 통제 실험을 진행했어요.
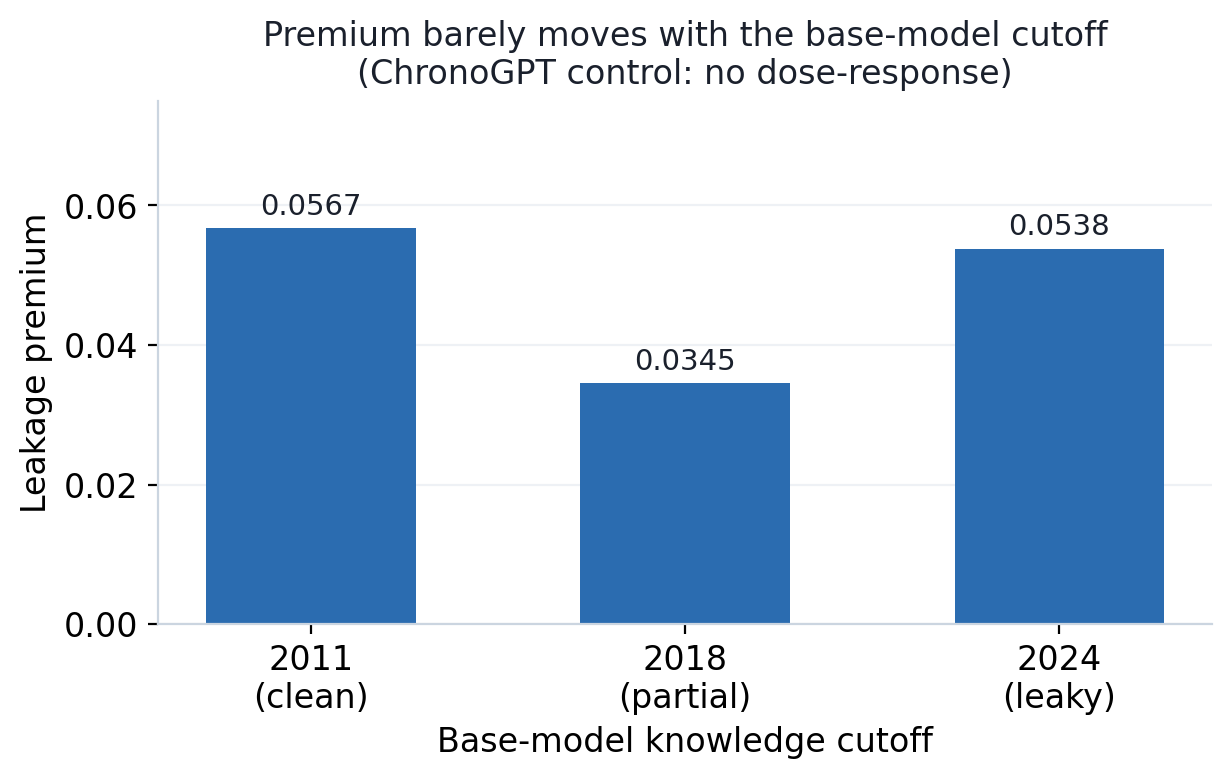
| 지식 마감 시점 | JPX 평가창(2021년 이후) | Leakage premium |
|---|---|---|
| 2011년 | 전혀 학습하지 않음(Clean) | 0.0567 |
| 2018년 | 일부 포함 | 0.0345 |
| 2024년 | 이미 학습함(Leaky) | 0.0538 |
결과적으로 모델의 지식 마감 시점이 미래로 이동한다고 해서 누수 프리미엄이 비례해 커지진 않았어요. 다만 이 통제 실험 자체는 검정력이 약해요. 미래 데이터를 전혀 학습하지 않은 2011년 모델과 이미 다 학습한 2024년 모델의 누수 프리미엄 차이가 −0.003에 불과하고, 95% 신뢰구간이 −0.40에서 0.07까지 0을 넓게 포함해요(1,000종목, 200 부트스트랩). 그래서 "효과가 전혀 없다"고 단정할 순 없지만, 적어도 누수 프리미엄이 사전 학습 시점에 따라 움직인다는 증거는 못 찾았어요.
즉, 이번에 측정한 누수 프리미엄은 모델이 미래를 기억해서라기보다 (B) 평가 시 시점 섞임으로 인해 발생한 구조적 누수라는 증거와 일치해요. 향후 이러한 시점 섞임(B)을 제어하기 위해 시간순으로 자르는 시계열 교차 검증(purged/embargoed time-series CV) 등 평가 프로토콜을 도입할 수 있지만, 이는 사전 학습 오염(A) 문제는 해결하지 못해요.
더 엄격한 기준선으로 다시 재봤어요
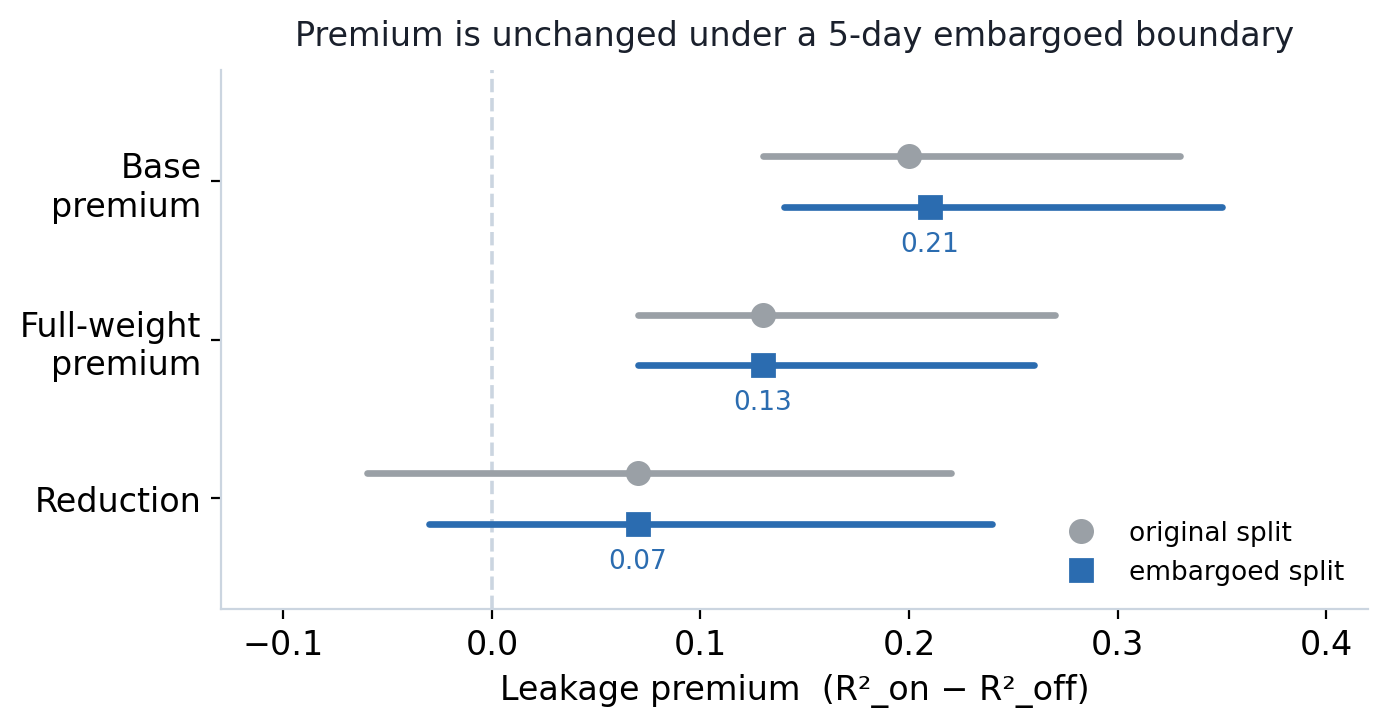
지금까지 측정한 누수 프리미엄은 시간순으로 데이터를 한 번 분리(학습 ≤ 2020-12-31, 평가 ≥ 2021-01-01)한 결과에 기대고 있어요. 평가가 우연이 아님을 확인하기 위해, 같은 베이스 모델과 전체 학습 체크포인트를 활용해 가벼운 강건성(Robustness) 점검 두 가지를 더 돌려봤어요.
학습과 평가 사이에 유예 기간(Embargo) 두기. JPX 대회의 예측 타깃은 약 2거래일 뒤의 수익률이에요. 그래서 2020년 12월 31일까지만 학습하도록 데이터를 나누면, 정답(라벨) 구간이 기준선을 살짝 넘어가 의도치 않게 미래 정보가 샐 수 있어요. 이를 막기 위해 미래 정보 차단 평가에 5일의 유예 기간을 두고 점수를 다시 매겼어요. 평가 구간(2021년 이후)은 그대로 두고 기준선 직전의 거래일들만 빼는 방식이죠.
결과적으로 미래 정보를 차단한 점수는 거의 변하지 않았어요. 베이스 모델은 −0.19에서 −0.20으로, 전체 학습 모델은 −0.16 그대로 유지됐거든요. 기존 기준선에서 정보가 새어나가지 않았다는 뜻이에요. 누수 프리미엄 역시 헤드라인 표와 거의 같아요. 베이스 모델은 0.21 [0.14, 0.35], 전체 학습 모델은 0.13 [0.07, 0.26]으로 두 모델 모두 신뢰구간이 0을 벗어났고, 프리미엄 감소폭은 0.07 [−0.03, 0.24]이에요.
정리하자면, 누수 프리미엄 자체는 기준선을 느슨하게 잘라서 생긴 착시가 아니에요. 그리고 모델 학습을 통해 프리미엄이 0.07만큼 줄어들긴 했지만, 이 감소폭의 신뢰구간에 0이 포함되어 있어요. 쉽게 말해 감소폭이 우연의 일치일 가능성을 배제할 수 없기 때문에, "학습을 통해 누수 문제가 확실히 해결됐다(통계적으로 유의미하다)"고 말하기는 어려워요. 다만 명확히 할 점은, 이건 기준선을 한 번 더 엄격하게 자른 것일 뿐, 데이터가 섞이는 그룹 K-폴드 방식을 시계열 교차 검증(Purged Time-series CV) 같은 더 엄격한 프로토콜로 바꾼 건 아니에요. 그 부분은 앞으로 해결해야 할 과제로 남아 있어요.
순차적 평가(Walk-forward)로 여러 시기 확인하기. 5단계로 확장한 순차적 평가는 특정 평가 창 하나만 보지 않아요. 확인 결과 베이스 모델은 −0.25, 전체 학습 모델은 −0.27로 둘 다 2021년 단일 기준일 때보다 더 낮은 점수를 기록했어요. 즉, 알파(초과 수익)가 없다는 결론이 특정 기준 시점 하나에서만 나오는 게 아니라 여러 시기에 걸쳐 일관되게 유지된다는 뜻이에요. (여기서는 전체 학습 모델이 베이스보다 근소하게 더 나빴어요. 2021년 기준일 때 보였던 작은 우위가 다른 시기에서는 이어지지 않으니, "학습이 도움됐다"가 아니라 "원래부터 알파가 없었다"고 해석하는 또 다른 근거가 돼요.)
Bryan Kelly 연구진과의 접근 차이
앞서 언급한 AQR Capital Management 소속이기도 한 예일대 브라이언 켈리(Bryan Kelly) 연구진은 4B 파라미터 모델을 시점 필터링된 텍스트로 처음부터(From-scratch) 학습하여 구조적으로 미래 정보의 유입을 원천 차단했어요.
반면 우리는 이미 2024년까지의 인터넷 데이터를 전부 학습한 상용 35B 베이스 모델 위에 10억 토큰을 추가 사전학습(CPT)하는 방식이었어요. 두 실험은 출발점 자체가 근본적으로 달라요.
단일 GPU LoRA와의 비교
단일 H100 LoRA 쿡북에서는 모델 파라미터의 약 2.6%만 가볍게 학습하는 LoRA 방식을 적용했어요.
| 지표 | LoRA 방식 | 전체 학습(이번 실험) |
|---|---|---|
| 학습 파라미터 | 약 945M(전체의 2.6%) | 35B(전체) |
| 학습 시간 | 23시간 23분(H100 1장) | 18시간 36분(H100 8장) |
| 학습 비용 | 약 56달러 | 약 378달러 |
| Premium reduction | 0.065 [−0.05, 0.18] | 0.07 [−0.06, 0.22] |
| 신뢰구간 0 배제 여부 | 아니요(방향만 맞음) | 아니요(방향만 맞음) |
비용은 전체 학습이 약 6.8배 비쌌지만, 두 방식 모두 신뢰구간에 0이 포함됐어요. 즉, LoRA가 학습하지 않은 나머지 97%의 파라미터가 누수의 핵심 병목이 아니었다는 뜻이에요. 토큰을 더 늘리기보다, 평가 프로토콜 자체를 손보는 것이 더 나은 해결책일 수 있어요.
한 가지 짚고 넘어갈 부분도 있어요. 위 표의 LoRA 감소폭 0.065는 단일 H100 LoRA 쿡북에서 학습한 LoRA 어댑터를 이 글과 같은 추론 스택(transformers 5.2 / torch 2.5)에서 다시 평가한 값이에요. 같은 스택에서 재면 LoRA 0.065와 전체 학습 0.07이 사실상 같죠. 반면 단일 H100 LoRA 쿡북은 자신의 스택(transformers 5.5 / torch 2.10)을 기준으로 감소폭 0.11, 베이스 누수 프리미엄 0.32를 보고해요. 이 글의 값(감소폭 0.065, 베이스 0.20)과 달라 보일 수 있죠.
하지만 이건 평가할 때마다 종목을 다시 뽑아서 생긴 차이가 아니에요. 두 평가 모두 같은 베이스를 같은 평가셋(1,000 종목, 5,817개 표본)과 같은 원본 데이터(JPX 원천 2,332,293행) 위에서 쟀고, 종목 선택도 시드(Seed) 고정이라 같은 설정으로 세 번 돌리면 베이스 R²가 소수점 넷째 자리까지 똑같이 나와요. 진짜 원인은 두 평가가 쓴 추론 스택(Inference stack)이 달라서예요. 같은 베이스라도 라이브러리 버전이 다르면 임베딩 값이 미세하게 달라지고 베이스 R²도 그만큼 움직여요. 그래서 쿡북끼리 절대값을 맞춰 보기보다, 각 평가가 내린 결론을 비교하는 게 맞아요. 두 평가 모두 베이스의 누수 프리미엄이 0을 유의하게 웃돌고 한 번의 학습으로는 유의하게 줄지 않는다는 결론은 같거든요(베이스 신뢰구간도 [0.13, 0.33]과 [0.22, 0.53]으로 서로 겹쳐요).
트레이딩 회사를 위한 요약
- 측정 도구는 작동했지만, 유의미한 감소는 없었어요. H100 8장과 35B 모델의 조합으로 누수 감소를 측정했지만, 95% 신뢰구간이 0을 포함하여 통계적으로 유의미한 감소는 확인하지 못했어요.
- 원인은 파라미터나 학습 토큰 수가 아닐 수 있어요. LoRA와 전체 학습 모두 유의미한 감소를 보이지 않았어요. 통제 실험을 통해 누수 프리미엄의 주범은 평가 방식인 그룹 K-폴드의 시점 섞임 현상과 관련이 깊다는 증거를 확인했으므로, 향후에는 날짜가 섞이지 않는 시계열 교차 검증 등 평가 프로토콜을 정밀화하는 쪽을 검토해 볼 수 있어요.
직접 테스트해 보세요
자체 포트폴리오 데이터로 실험해 보고 싶다면 VESSL Cloud의 8×H100 SXM 환경을 추천해요. 70B 이상의 대형 베이스 모델이나 멀티 노드 학습이 필요하다면 언제든 sales@vessl.ai로 문의해 주세요. L40S부터 B300까지 다양한 GPU를 보유하고 있어요.
자주 묻는 질문
이 실험으로 알파(초과 수익)나 수익 모델이 나왔나요?
왜 LoRA가 아니라 전체 학습(full-weight)을 했나요?
누수 프리미엄이 진짜인가요, 통계 착시인가요?
GPU 8장보다 적게도 되나요?
실행 코드는 어디 있나요?
부록 A: 왜 H100 한 장으로는 부족할까요?
이유는 단순해요. 메모리 때문이에요.
35B 전체를 학습하려면 먼저 GPU에 무엇이 올라가는지부터 봐야 해요. 35B 파라미터를 bf16으로 저장하면 모델 자체만 70GB예요. H100 80GB 한 장에 겨우 들어가는 크기죠.
하지만 학습에는 모델만 필요한 게 아니에요. AdamW 옵티마이저는 파라미터 1개당 세 가지 정보를 추가로 들고 있어요.
- fp32 마스터 카피(master copy): 정밀한 32비트 복사본 (파라미터당 4바이트)
- m(1차 모멘트): 그래디언트의 지수이동평균 (4바이트)
- v(2차 모멘트): 그래디언트 제곱의 지수이동평균 (4바이트)
bf16 모델 파라미터는 학습 중에 fp32 마스터 카피를 기준으로 업데이트돼요. m과 v는 매 업데이트의 방향과 크기를 보정하고요. 이 세 가지가 학습 내내 GPU 메모리에 올라가 있어야 해요.
계산해 보면 이래요.
- 350억 파라미터 × 4바이트 × 3 = 약 420GB
H100 한 장(80GB)으로는 5배 넘게 모자라요. 여기에 활성화 값(activation, 순전파 때 계산되는 중간값)과 그래디언트(Gradient, 역전파 때 계산되는 업데이트 방향 신호)까지 더하면 더 커지죠.
양자화(Quantization, 숫자를 더 적은 비트로 압축)로 욱여넣을 수도 있어요. 하지만 이 실험에서는 정밀도가 결과를 바꿀 수 있어요. 그래서 측정 품질을 흔들 수 있는 선택은 피했어요.
결국 GPU 한 장으로는 끝낼 수 없어요. 모델이 한 장에 안 들어가면 여러 장에 나눠 담아야 하죠.
그 방법이 FSDP(Fully Sharded Data Parallel)예요. 모델 파라미터, 그래디언트, 옵티마이저 상태를 N개의 GPU에 1/N씩 쪼개 담아요. 계산할 때는 각 GPU가 자기 차례에 필요한 파라미터만 모았다가, 계산이 끝나면 다시 쪼개고요.
8장으로 나누면 부하가 확 줄어요. 420GB짜리 옵티마이저 상태는 카드당 약 52GB로, 70GB짜리 모델 가중치와 70GB짜리 그래디언트는 카드당 각각 약 8.75GB로 줄어들죠. 단순 합산하면 카드당 약 70GB로, 80GB H100 한 장에 겨우 들어가요. 다만 이건 상한 추정치라서, 아래 디버깅 섹션에서 실제 학습이 메모리를 어디까지 끌어올리는지 실측값으로 확인해요.
그래서 35B 전체 학습의 현실적인 출발점이 VESSL Cloud의 8×H100 SXM 등급이에요. 70B 이상 베이스나 멀티 노드 학습처럼 더 큰 작업이라면 B200이나 Rubin(NVIDIA의 차세대 데이터센터 GPU) 확장도 검토할 수 있어요. GPU가 필요하면 sales@vessl.ai로 연락 주세요.
부록 B: H100 8장에 모델을 올리기까지의 실험기
"이론적으로 가능하다"와 "학습이 실제로 돈다"는 다른 얘기예요. 첫 실험부터 OOM(Out of Memory, 메모리 부족)이 터졌거든요. 이 섹션은 그 디버깅 로그예요. 측정 결과는 위에 다 있으니, 엔지니어링이 궁금할 때만 읽어도 돼요.
단순한 메모리 부족이 아니었어요
먼저 좋은 신호가 있었어요. 2×H100 LoRA 사전 검증 실행(dry-run)은 깨끗하게 통과했거든요. FSDP2가 이 하이브리드 어텐션 모델(두 가지 어텐션 방식을 한 모델에 섞은 구조)을 잘 샤딩한다는 뜻이었죠.
문제는 LoRA를 떼고 35B 전체를 학습시켜도 GPU 메모리에 들어가느냐였어요.
첫 실험의 답은 분명했어요. 안 들어갔거든요. 그런데 이유가 바로 보이진 않았어요.
Setup: 8×H100 SXM, axolotl 0.16, FSDP2,
optimizer adamw_torch_fused, seq_len 4096,
gradient_accumulation_steps 4
Result: OOM at first backward
GPU 1: 506 MiB free of 79.18 GiB total,
75.26 GiB held by PyTorch
Tried to allocate 1024 MiB → allocation failed메모리 계산만 놓고 보면 이상했어요. 8장에 나눠 담으면 GPU당 샤딩된 파라미터가 약 8.75GB, 샤딩된 그래디언트도 약 8.75GB예요. 활성화 체크포인팅(Activation Checkpointing, 일부 중간값을 저장하지 않고 역전파 때 다시 계산해 메모리를 아끼는 기법)을 켜면 계산 중간에 필요한 추가 파라미터가 약 1.75GB 정도고요. 활성화 값 자체는 시퀀스 길이 4096에서 몇 GB 수준이에요.
다 합쳐도 GPU당 약 20~25GB를 예상했어요. 그런데 실측값은 73~75GB였죠. 예상보다 약 50GB를 더 쓰고 있었어요.
한 가지가 더 헷갈렸어요. OOM이 첫 optimizer.step()(옵티마이저가 실제로 파라미터를 업데이트하는 단계) 전에 터졌거든요. 옵티마이저의 추가 상태는 아직 할당조차 안 된 시점이었죠.
그래서 옵티마이저를 paged_adamw_8bit(8비트 양자화 AdamW)로 바꾸고 시퀀스 길이를 4096에서 2048로 줄여봤어요. 두 변경 모두 가설을 좁히는 데 도움이 됐죠. 8비트 옵티마이저는 효과가 없었어요. 상태를 첫 스텝 안에서 늦게(lazily) 할당하기 때문에 OOM 시점엔 영향이 없거든요. 시퀀스를 절반으로 줄여도 약 2GB밖에 안 줄었고요. 사라진 50GB는 그대로였어요.
OOM 발생 시점이 힌트였어요
진단 후보는 둘이었어요.
가설 A: 추가 메모리는 샤딩 안 된 옵티마이저 상태다. bitsandbytes(8비트 옵티마이저 라이브러리)가 FSDP2의 DTensor(분산 텐서, 샤딩된 파라미터를 추적하는 PyTorch 구조)를 이해하지 못해서, 35B 전체 모델의 fp32 마스터 카피를 GPU마다 통째로 할당한다는 거예요.
가설 B: 추가 메모리는 샤딩 안 된 그래디언트다. gradient_accumulation_steps > 1(여러 작은 배치를 모아 큰 배치 효과를 내는 것)일 때, FSDP가 no_sync()(그래디언트를 모으는 동안 GPU 간 동기화를 잠깐 끄는 모드) 안에서 들고 있는 그래디언트가 문제라는 거예요. PyTorch FSDP 문서가 이걸 분명히 밝혀요.
FSDP will accumulate the full model gradients (instead of gradient shards) until the eventual sync.
즉, 여러 마이크로배치에 걸쳐 그래디언트를 모으는 동안 FSDP는 각 GPU에 샤딩된 게 아니라 샤딩 안 된 전체 그래디언트를 들고 있어요.
OOM이 첫 역전파에서 터졌다는 사실이 답을 갈랐어요.
bitsandbytes는 옵티마이저 상태를 init이 아니라 첫 optimizer.step() 안에서 늦게 할당해요. 가설 A가 맞다면 OOM은 첫 스텝에서 터졌어야 하죠. 그런데 실제 OOM은 스텝이 한 번도 돌기 전, 첫 역전파에서 터졌어요. 가설 A의 타이밍이 안 맞았죠.
반대로 가설 B는 정확히 들어맞았어요. gradient_accumulation_steps: 4면 Accelerate(Hugging Face의 분산 학습 보조 라이브러리)가 매 스텝 첫 3개 마이크로배치(작은 누적 배치)에서 그래디언트 동기화를 막아요. 그 no_sync 구간 동안 FSDP는 각 GPU에 샤딩된 게 아니라 35B 전체 그래디언트를 들고 있고요.
그게 bf16으로 최대 70GB짜리 샤딩 안 된 그래디언트예요. 여기에 샤딩된 파라미터, 계산 중간에 필요한 추가 파라미터, 활성화 값, 버퍼까지 더하면 73~75GB에 도달하죠. 실측값과 계산이 맞아떨어졌어요.
쉽게 말하면 이래요. 보통 FSDP는 매 역전파마다 그래디언트를 GPU에 쪼개 담아 GPU당 메모리를 1/N로 유지해요. 그런데 no_sync() 동안은 그 동작이 멈춰요. 그 구간에 누적된 그래디언트는 각 GPU에 전체 모델 크기로 남아 있죠. 모델 파라미터는 샤딩되는데, 그래디언트만 각 GPU에 통째로 남는 거예요.
해결은 한 줄이었어요.
- gradient_accumulation_steps: 4
+ gradient_accumulation_steps: 1다시 돌리자 첫 역전파가 통과했고, 학습이 시작됐어요.
이게 왜 헷갈리냐면요. 그래디언트 누적(gradient accumulation)은 보통 메모리를 아끼는 도구예요. 작은 배치를 쌓아 큰 배치처럼 학습하니까, OOM이 나면 자연스럽게 손이 가는 선택이죠. 그런데 FSDP는 그 기대를 뒤집어요.no_sync()때문에 누적 구간 동안 그래디언트가 샤딩 안 된 채로 각 GPU에 전체 모델 크기로 남거든요. 그래서 쿡북의 최종 config는gradient_accumulation_steps=1을 명시하고, PyTorch 문서를 인용한 주석을 달아뒀어요.
마지막 정리: 옵티마이저와 활성화 체크포인팅
그래디언트 누적 수정이 구조적인 해결이긴 했지만, 끝은 아니었어요. paged_adamw_8bit가 optimizer.step()에서 곧장 RuntimeError로 죽었거든요.
RuntimeError: mixed torch.Tensor and DTensor
at bitsandbytes/optim/optimizer.py:520
→ optimizer_update_32bitbitsandbytes #1633에 등록된 비호환 문제예요. 8비트 Adam의 상태 업데이트 커널(GPU에서 도는 작은 함수)이 FSDP2의 DTensor로 감싼 샤딩된 파라미터를 처리할 줄 몰랐던 거죠.
그래서 옵티마이저를 adamw_torch_fused로 바꿨어요. PyTorch가 직접 만든 거라 FSDP2와 호환되고, DTensor 혼란도 없거든요. 비용은 있어요. 8비트 옵티마이저보다 GPU당 약 17.5GB의 샤딩된 fp32 마스터 카피가 더 들죠. 하지만 그래디언트 누적 수정으로 50GB를 비워둔 덕에 여유가 있었어요. 활성화 체크포인팅을 켠 상태에서 피크 메모리는 약 42GB로 안정됐고요.
마지막으로 활성화 체크포인팅을 껐어요. 역전파 때 중간값을 다시 계산하는 대신 그냥 메모리에 들고 있는 거죠. 메모리는 더 쓰지만 학습이 빨라져요. adamw_torch_fused 프로파일은 활성화 체크포인팅을 켜면 42GB에서 피크를 찍고 약 37GB가 남았어요. 이 여유를 처리량 +32%와 맞바꿀 수 있었죠. 18시간이 넘는 학습에서 +32%는 하루 안에 끝내느냐, 크레딧 예산을 넘기느냐를 가르는 차이예요. 끄자 피크는 51GB로, 약 29GB의 여유가 남았어요.
이 수정들을 거치며 config가 안정됐어요. 실제 학습은 56,430 스텝, 에폭 1.0을 train_runtime 기준 18시간 36분에 끝냈어요. 최종 학습 손실(train loss)은 2.182였고요.
학습은 끝났는데, 작업이 실패했어요
학습은 완료됐는데 잡은 failed 상태로 끝났어요. 시간순으로 로그를 보면 이래요.
01:07:30에 마지막 스텝(56,430 / 56,430, 에폭 1.0)이 통과했어요. 학습 연산은 여기서 끝난 거죠.01:21:28에 Trainer가Training completed!를 출력하고 샤딩된 체크포인트(checkpoint-56430)를 디스크에 안전하게 썼어요. train_runtime 66,980초(18시간 36분)가 여기 기록됐고요.- 바로 다음, axolotl이 FSDP 샤드들을 같은 분산 잡 안에서 하나의 가중치로 병합하기 시작했어요(
merge_sharded_fsdp_weights). rank 0이 66GB짜리 병합 파일을 오브젝트 스토리지(네트워크 볼륨)에 쓰는 동안, 나머지 7개 rank는 단일 ALLREDUCE에서 대기했죠. - 그 병합 쓰기가 30분을 넘겼어요.
01:51:28에 NCCL 워치독이 그 콜렉티브를 시간 초과로 판정했고요.
[Rank 1] Watchdog caught collective operation timeout:
WorkNCCL(SeqNum=7122731, OpType=ALLREDUCE, Timeout(ms)=1800000)
ran for 1800092 milliseconds before timing out.
→ c10::DistBackendError → all ranks terminated → job state failed즉, 학습이 실패한 게 아니에요. 학습이 완전히 끝난 뒤, 마지막 병합 단계의 분산 배리어가 타임아웃 난 거죠. 정작 필요한 checkpoint-56430은 이미 디스크에 안전하게 있었어요. NCCL 워치독 타임아웃은 이미 기본 10분에서 30분으로 올려뒀는데도, rank 0의 66GB 네트워크 쓰기가 그걸 넘겨버린 거예요.
해결은 분산을 빼는 거였어요. GPU 한 장짜리 단일 프로세스 잡을 따로 띄워, checkpoint-56430의 샤드들을 오프라인에서 다시 병합했죠(16개 샤드, 66GB bf16). NCCL 배리어가 없으니 타임아웃도 없었어요. 위 결과의 평가는 이 병합된 체크포인트로 돌렸고요.
여기서 얻은 교훈은요. 큰 FSDP 체크포인트의 최종 병합을 분산 잡 안에서 돌리면, rank 0의 수십 GB짜리 네트워크 쓰기가 NCCL 콜렉티브 워치독보다 오래 걸려서, 학습이 100% 끝난 잡을 죽일 수 있어요. 그래서 쿡북의 최종 절차는 학습 중에는 샤딩된 체크포인트만 유지하고(SHARDED_STATE_DICT), 병합은 학습이 끝난 뒤 분산이 필요 없는 단일 프로세스 잡에서 따로 돌려요. 그렇게 병합된 가중치가 VESSL Cloud의 오브젝트 스토리지에 안착했어요.관련 자료
- 멀티GPU 쿡북: 8×H100 35B 추가 사전학습 재현 레시피: 이 글을 재현하는 레시피(확정된 config 값, FSDP2 메모리 디버깅 로그, 비용, 운영 점검)
- Single-H100 LoRA 쿡북: LoRA로 같은 측정: 비교 기준(945M 어댑터, GPU 1장, 약 56달러)
- Kelly, Bryan, et al. "Scaling Point-in-Time Language Models." SSRN Working Paper No. 6681860
- He, Songrun, Linying Lv, Asaf Manela, and Jimmy Wu. "Chronologically Consistent Large Language Models." arXiv:2502.21206
- PyTorch FSDP no_sync() docs
- Accelerate gradient synchronization 가이드
- bitsandbytes #1633: FSDP2와 8비트 Adam의 DTensor 비호환
VESSL AI
뉴스레터 구독
AI 인프라 구축 노하우와 최신 GPU 소식을 매달 보내드려요.