A100 vs H100 vs B200: LoRA 학습·추론 비용 벤치마크

이 글은 VESSL AI 팀이 직접 측정한 결과이고, VESSL Cloud 소개를 포함해요. 모든 비용은 절대 금액 없이 상대 인덱스로만 표기했어요.
31B 모델을 파인튜닝하고 서빙하려고 하면 첫 고민은 "어떤 GPU를 빌릴까"예요. 익숙한 A100, 더 빠른 H100, 새로 나온 B200 중에서요. 보통 "최신 칩은 비싸고 구형은 싸다"고 생각하는데, 직접 재 보니 그 직감은 대체로 틀렸어요.
같은 LoRA 파인튜닝·추론 워크로드를 google/gemma-4-31B-it로 8× A100, 8× H100, 8× B200에서 돌리고, 양자화와 서빙 설정을 각각 스윕한 뒤 토큰당 비용으로 정규화했어요. 결론은 두 가지예요. 첫째, 각 플랫폼을 제대로 튜닝하면 토큰당 비용은 서로 약 5% 안쪽이에요. 즉 토큰당 가격은 사실상 동률이라, 이걸로 GPU를 고를 필요가 없어요. 둘째, 비용이 비기면 남는 기준은 속도와 "얼마나 많이 서빙할 수 있나"인데, 둘 다 신형 B 시리즈가 앞서요. 특히 여러 GPU로 확장할수록 더요. 이 관점으로 글을 풀어갈게요.
본격적인 수치 전에, 직접 따라 해 보고 싶다면 15분 만에 끝내는 Gemma 4 파인튜닝 가이드가 셋업을 처음부터 끝까지 다뤄요.
핵심 요약
- 토큰당 비용은 약 5% 동률이에요. 튜닝하면 A100·H100·B200이 토큰당 ~5% 안에 들어와요. 그러니 토큰당 가격으로 GPU를 고르지 말고, 속도와 서빙 용량으로 고르세요. 거기선 B 시리즈(B200)가 이겨요.
- 학습: B200은 같은 작업을 GPU-시간 약 4분의 1로 끝내요. FSDP(gradient checkpointing 끄기)가 기본 DDP보다 빠르고, FP8은 Blackwell에서 Transformer Engine +
torch.compile일 때만 이득이에요. naive FP8은 오히려 느려요. - 추론: B200이 A100보다 토큰/초를 10배 넘게 서빙해요(단, FP8 vs bf16과 메모리 용량 차이가 섞인 값이지 순수 실리콘 차이는 아니에요). 가장 큰 단일 효과는 FP8 KV 캐시(+44~57%)이고, speculative decoding은 draft 길이 2가 최적점이에요.
- LoRA와 speculative decoding은 함께 써도 돼요. 수용률이 base 모델 대비 0.3%p 이내로 유지됐어요. 단 이건 LoRA가 base에 가깝기 때문이고, 풀 파인튜닝은 draft 모델을 갱신해야 할 수 있어요.
- 모든 수치는 8-GPU 결과예요. FSDP와 높은 동시성 서빙은 여러 GPU가 있어야 가능하니, 멀티 GPU 노드로 가야 이 경제성을 얻어요.
- 결론: 학습도 추론도 멀티 GPU B 시리즈를 기본으로 두고, 워크로드가 허용할 때만 H100·A100으로 내리세요.
실험 설정
비교가 공정하도록 워크로드를 하드웨어 전반에 동일하게 맞췄어요.
- 모델:
google/gemma-4-31B-it, LoRA(rank 16, alpha 32, 레이어당 어텐션·MLP projection 7개 전체)로 파인튜닝. - 학습 데이터: ShareGPT 일부, 시퀀스 길이 2,048로 패킹.
- 추론: vLLM로 ShareGPT 프롬프트 1,000개 서빙, H100·B200은 모델의 FP8 빌드 사용.
- 하드웨어: 8× A100(bf16), 8× H100(fp8), 8× B200(fp8), 실행당 8 GPU.
- 비용: 아래 모든 비용 수치는 상대 인덱스예요. 가장 잘 튜닝한 A100 실행을 1.00으로 정규화했고, 절대 금액은 싣지 않아요.
워크로드는 둘, 이야기도 둘이에요. 학습부터 볼게요.
학습: 속도와 비용은 다른 질문이에요
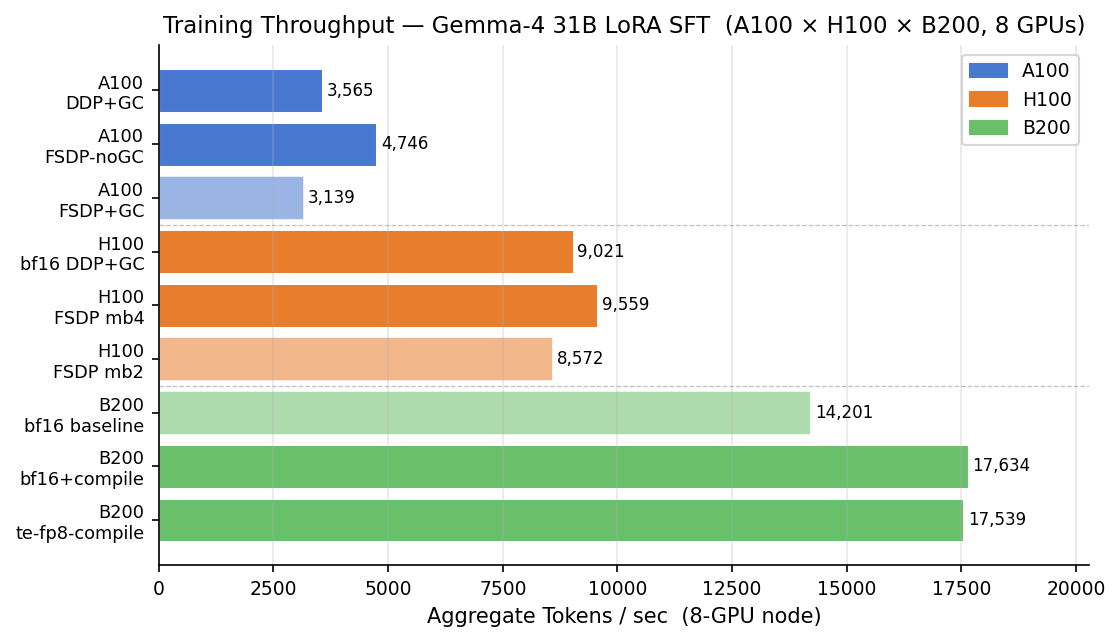
순수 학습 처리량 순위는 예상 그대로예요. 토큰/초 기준으로 B200은 A100보다 약 4.0배, H100보다 약 1.6배 빠르고, H100은 A100보다 약 2.5배 빨라요. 학습을 최대한 빨리 끝내는 게 목표라면 B200이 압도적이에요. 최적 설정에서 220 스텝 실행을 A100 기준 GPU-시간의 약 5분의 1로 끝내요.
토큰당 비용은 다른 질문이에요. 빠른 하드웨어는 시간당 요금도 비싸니까요. 이걸 정규화하면 그림이 확 평평해져요.
| 플랫폼별 최적 설정 | 처리량(토큰/초) | 상대 토큰당 비용 |
|---|---|---|
B200 — bf16 + torch.compile | 17,634 | 1.05 |
| H100 — FSDP + checkpointing, micro-batch 4 | 9,559 | 1.04 |
| A100 — FSDP, gradient checkpointing 끔 | 4,746 | 1.00 |
| A100 — 표준 DDP + checkpointing | 3,565 | 1.33 |
비용 열은 거의 안 움직여요. 튜닝하면 A100·H100·B200 모두 토큰당 약 5% 안에 들어오고, 완벽히 설정했을 때만 A100이 근소하게 가장 낮아요. 그래서 이 표는 처리량 열로 읽는 게 맞아요. B200은 같은 학습을 훨씬 짧은 wall-clock time에 끝내요. 기다림이 줄고, 반복이 빨라지고, GPU를 잡아두고 기다리는 날이 줄어든다는 뜻이에요. 비용이 비긴다는 게 오히려 핵심이에요. B 시리즈로 토큰당 더 내지 않으면서 그 속도를 얻으니까요. (이 수치들은 8-GPU 결과이고, 가장 싼 A100 설정조차 FSDP로 모델을 8개 GPU에 샤딩해야 이 경계선에 닿아요. 바로 다음에 설명할게요.)
FSDP가 뻔한 기본값을 이겨요
8개 GPU로 파인튜닝하는 표준 방식은 메모리를 아끼려고 gradient checkpointing을 켠 DDP예요. 그런데 gradient checkpointing을 끈 FSDP(Fully Sharded Data Parallel)가 A100·H100 양쪽에서 더 빠르고 쌌어요. 파라미터를 GPU마다 샤딩하면 메모리가 충분히 확보돼서, gradient checkpointing을 아예 끄고 더 큰 micro-batch를 돌릴 수 있어요.
효과가 커요. A100 FSDP(체크포인팅 끔)는 4,746 토큰/초로, DDP 기본값 3,565보다 약 33% 빨라요. H100에서는 micro-batch 2의 FSDP가 GPU당 단 7.6 GB로 8,572 토큰/초를 내요. DDP 설정의 약 60 GB와 비교하면, 같은 처리량을 메모리 일부만으로 내는 거예요.
FP8 학습은 제대로 안 하면 함정이에요
FP8은 거저 얻는 이득처럼 들려요. 바이트가 절반이니 더 빠르고 싸야 하죠. 그런데 맞는 FP8 경로가 아니면 그렇지 않아요.
- naive FP8은 B200에서 bf16의 0.48배 처리량에 메모리는 2.2배였어요. bf16보다 느리고 더 먹어요.
- H100의 FP8 학습도 역효과였어요. bf16이 더 싼 선택이었어요.
- 예외는 B200의 Transformer Engine FP8 +
torch.compile이에요. 테스트한 전 구성 중 가장 빠른 wall-clock time을, bf16 대비 +23% 처리량으로 달성했어요.
정리하면, 학습에서 FP8은 Blackwell의 Transformer Engine + torch.compile로만 쓰세요. 그 외에는 bf16 + FSDP가 비용 효율 기본값이에요.
하드웨어별로 학습이 안정적인가요?
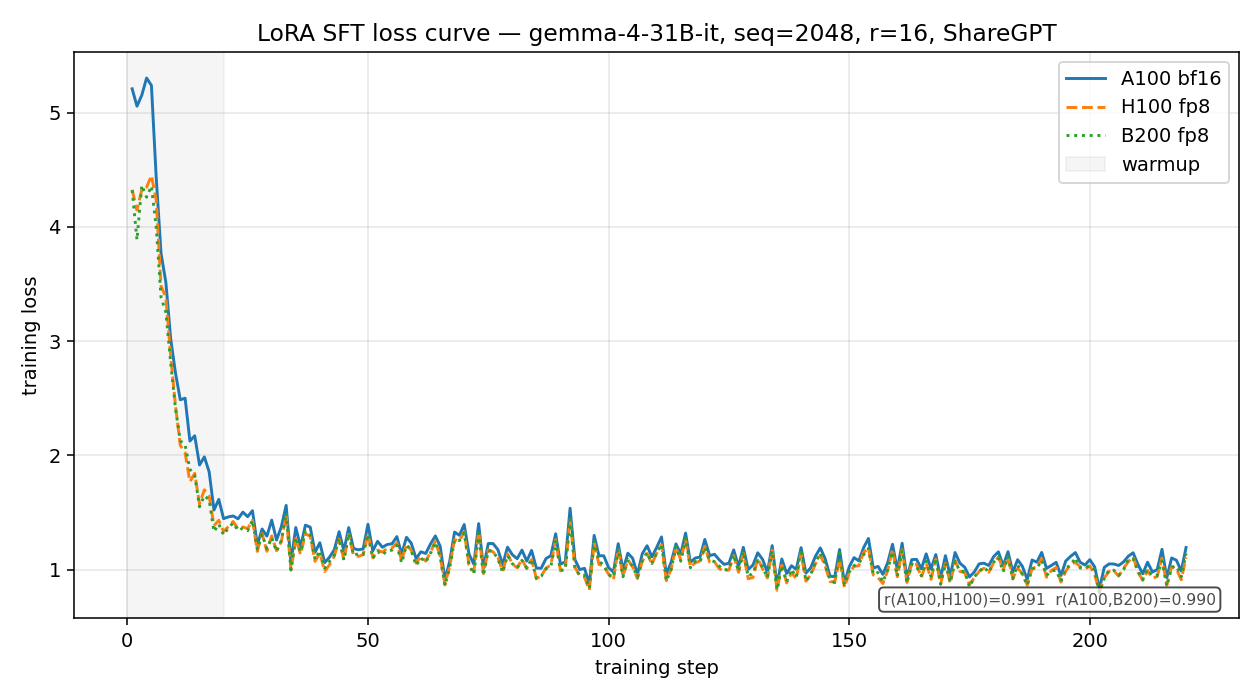
세 플랫폼 모두 비슷한 최종 loss(1.11~1.19)로 수렴해서, 학습된 어댑터는 어디서 돌리든 비슷해요. 차이는 워밍업에서 나타나요. A100 실행이 gradient norm 스파이크가 가장 컸고(첫 30스텝에서 약 1,650 피크) gradient 이상도 가장 많았어요. H100·B200은 훨씬 잔잔했어요(피크 220~235로 A100의 약 7분의 1). 발산한 실행은 없었지만, A100에서 파인튜닝한다면 워밍업을 보수적으로 잡고 첫 30스텝을 지켜보세요.
추론: 신형 하드웨어가 진가를 보이는 곳이에요
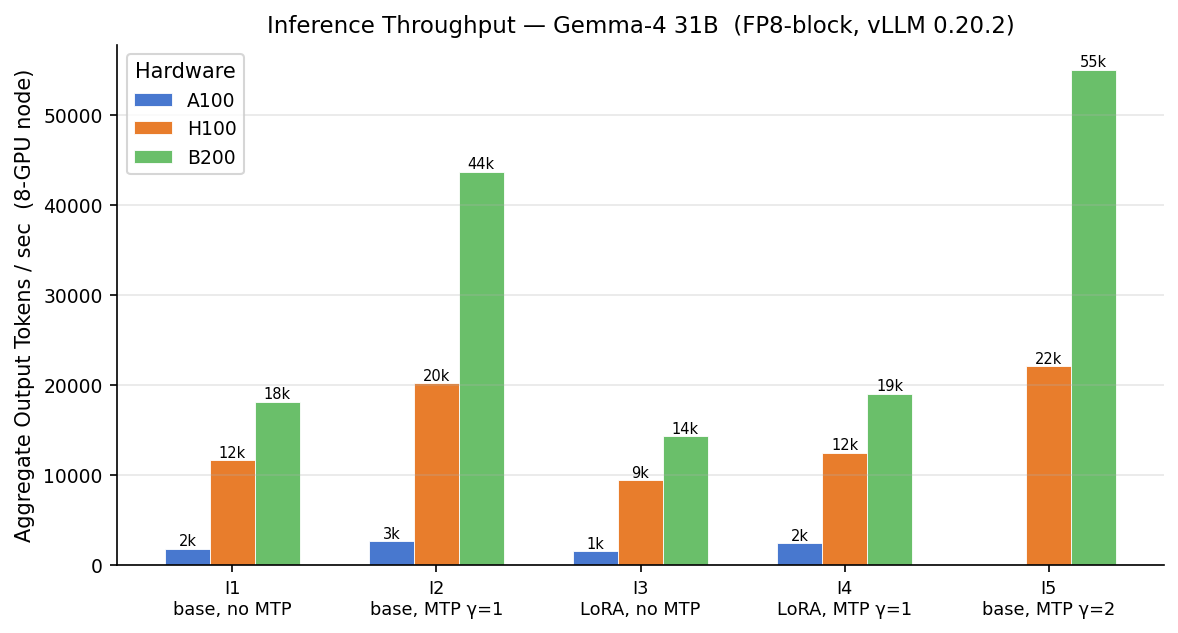
학습 비용이 거의 무승부였다면, 추론은 압승이에요. 별다른 최적화 없는 기본 처리량에서 B200은 A100보다 토큰/초가 10.2배, H100은 6.5배 많아요. 추론은 메모리 대역폭에 묶이는데, 신형 칩이 앞서는 지점이 바로 거기예요. 그래서 추론의 토큰당 비용 격차는 크고, H100이 A100보다 이 모델을 약 3~5배 싸게 서빙해요. 추론을 신형 하드웨어에 몰아주는 게 학습보다 훨씬 이득이에요.
그 10배 수치엔 솔직한 단서가 하나 있어요. 실제로 배포 가능한 차이가 맞지만, 순수 실리콘 차이는 아니에요. 두 가지가 격차를 키워요. 첫째, A100은 native FP8을 지원하지 않아 bf16로 돌고 H100·B200은 FP8로 도는데, FP8이 메모리 트래픽을 약 절반으로 줄여서 우위의 일부는 정밀도 덕이지 하드웨어가 아니에요. 둘째, 이 값들은 각 플랫폼의 최적 동시성에서의 집계치인데, A100은 80 GB라 모델 가중치를 빼면 KV 캐시에 약 10 GB만 남아 훨씬 낮은 동시성에서 포화돼요. 반면 B200은 192 GB라 계속 확장돼요. 즉 이 비교는 각 카드에서 실제로 돌릴 수 있는 범위(곧 실제 비용에 영향을 주는 값)를 반영한 거지, 순수 칩 속도만 분리한 게 아니에요. 칩 클럭 속도 결과가 아니라 비용·용량 결과로 읽어 주세요.
하드웨어 선택보다 더 중요한 최적화가 둘 있어요.
Speculative decoding(MTP), 그리고 LoRA와도 잘 돼요
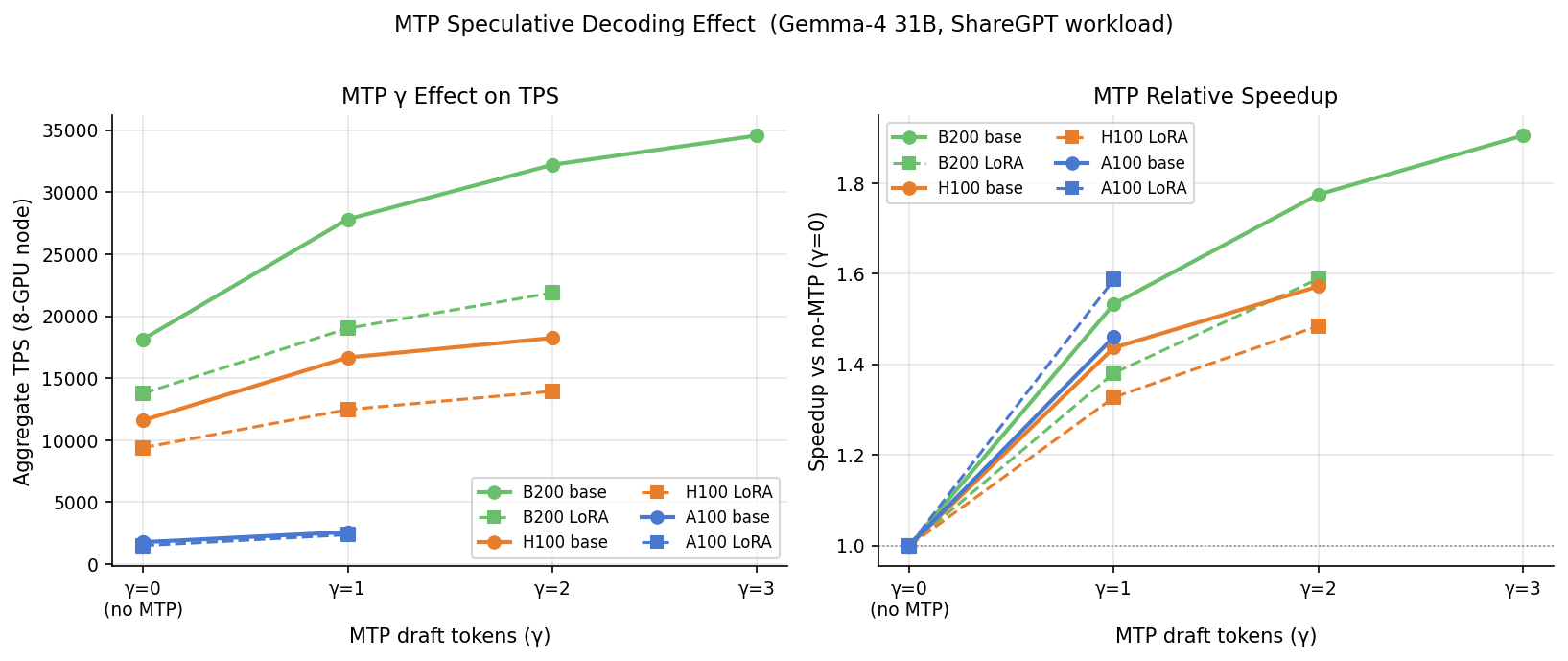
Multi-token prediction(MTP)은 모델이 토큰 여러 개를 미리 draft로 만들고 한 번에 검증하게 해요. 한 토큰 앞서 draft를 만들면 B200 처리량이 수용률(acceptance rate) 82.8%에서 53% 올라요. 두 번째 draft 토큰은 16%를 더 더하지만 수용률은 73%로 떨어져요. 세 번째는 7%만 더해요. 실용적 최적점은 draft 길이 2예요.
가장 궁금했던 질문이에요. LoRA 어댑터를 hot-load한 상태에서도 speculative decoding이 될까요? 돼요. 그리고 당연한 건 아니었어요. draft 모델은 수정되지 않은 base 모델이라, 파인튜닝이 타깃 출력을 draft에서 멀어지게 해 수용률을 떨어뜨릴 수도 있었어요. 그런데 LoRA에서는 거의 안 움직였어요. base와 LoRA 모델의 차이가 모든 플랫폼에서 0.3%p 이내로, draft 길이 1에서 약 83%를 유지했어요. rank-16 LoRA 어댑터는 모델을 draft의 기준인 base에서 크게 벗어나지 않게 하거든요. 이 수용률은 세 GPU 모두에서, 그리고 같은 모델의 다른 실행에서도 똑같이 나왔어요. LoRA와 speculative decoding은 함께 출시해도 돼요.
솔직하게 짚을 단서가 하나 있어요. 이건 "LoRA라서" 성립해요. 풀 파인튜닝은 모든 가중치를 갱신해 모델을 base draft에서 훨씬 멀어지게 할 수 있어서, draft 모델을 다시 학습하거나 교체하지 않으면 수용률, 그리고 speculative decoding 가속이 낮아질 수 있어요. 우리는 LoRA만 측정했으니, 풀 파인튜닝은 보장이 아니라 열린 질문으로 봐 주세요.
FP8 KV 캐시가 단일 최대 효과 설정이에요
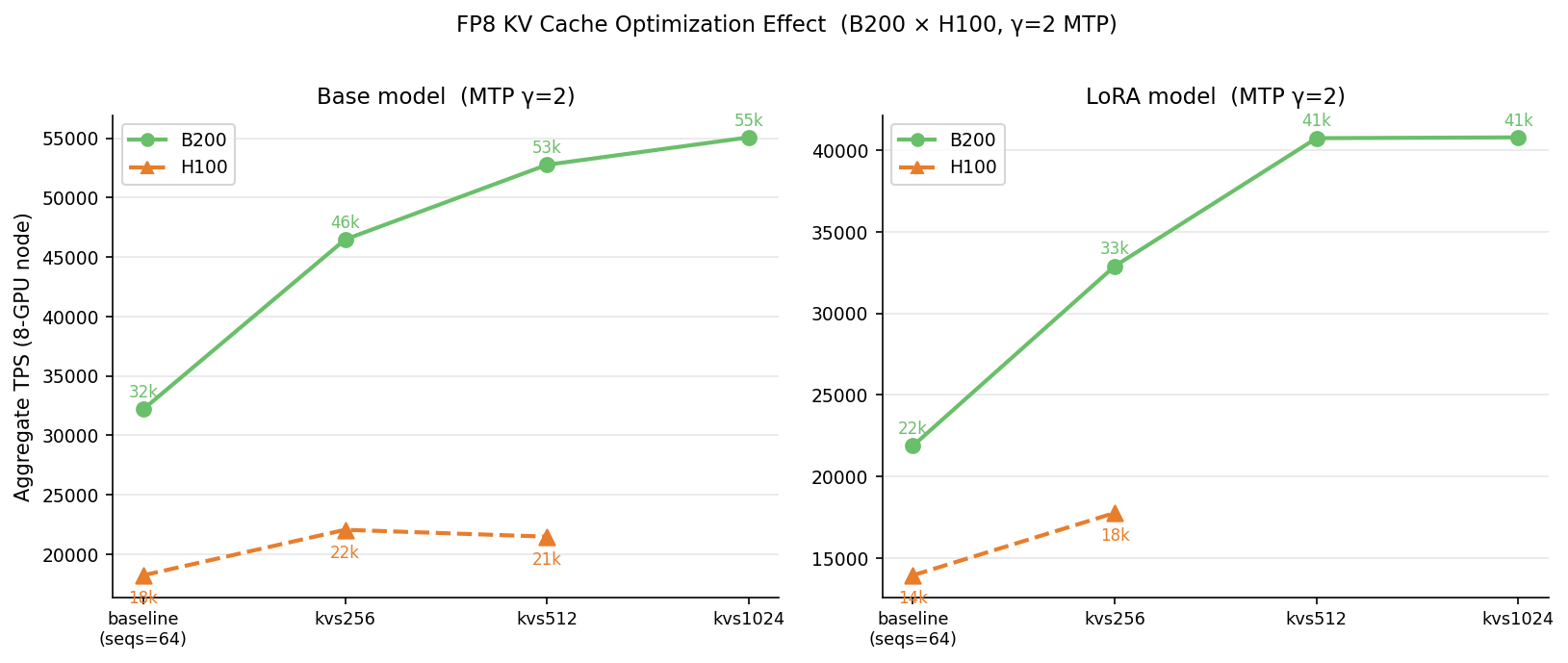
KV 캐시를 FP8로 저장하면 메모리 사용량이 절반이라, 한 번에 훨씬 많은 시퀀스를 서빙할 수 있어요. 이게 전체 연구에서 가장 큰 단일 개선이었어요. 이미 최적화된 설정 위에서 +44~57% 처리량을 더했어요. B200에서 LoRA + draft 길이 2 + 동시 시퀀스 512의 FP8 KV 캐시를 합치면 40,734 토큰/초에 도달했어요. 최적화하지 않은 base 모델보다 높아요. 최적화가 LoRA 서빙 오버헤드를 충분히 메우고도 남았어요.
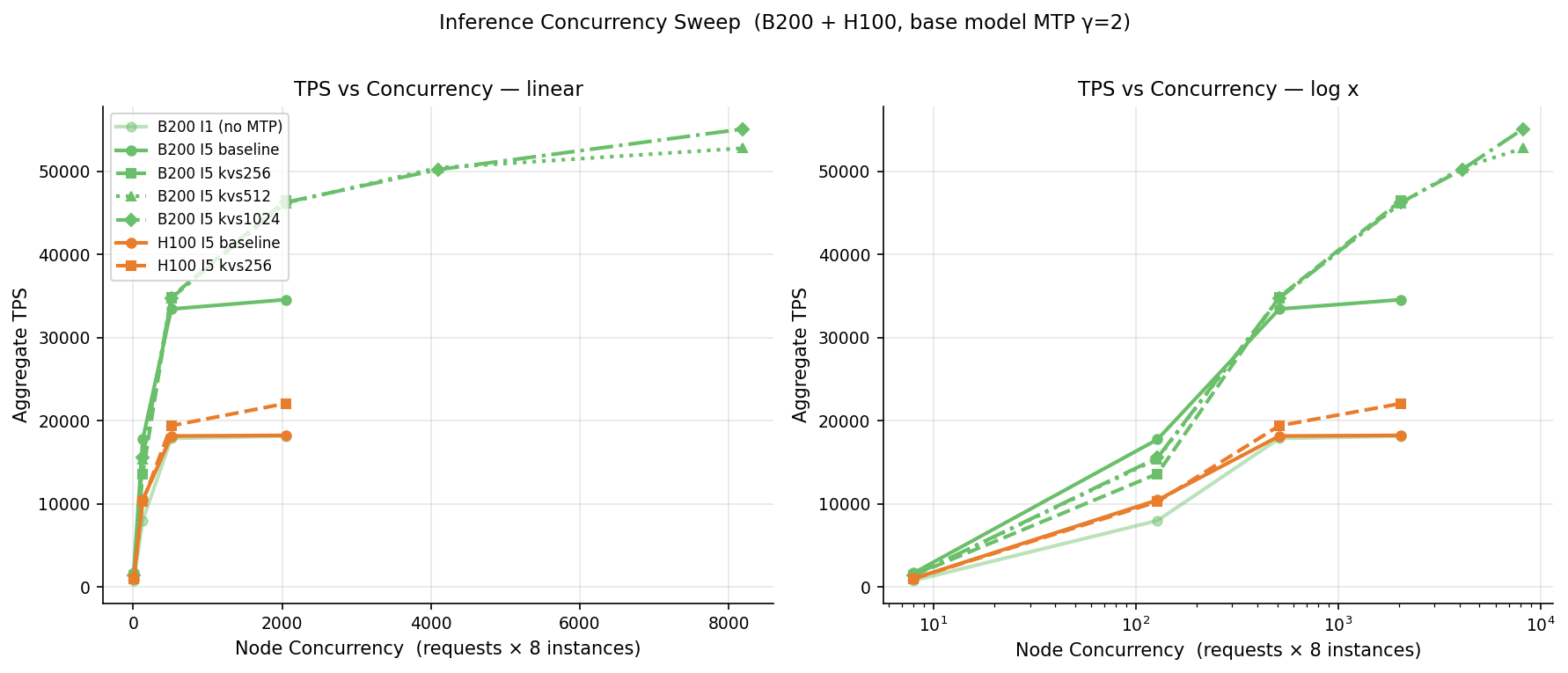
FP8 KV 캐시는 포화점도 오른쪽으로 밀어요. B200 처리량은 동시 시퀀스 8,000을 넘어서도 계속 올라 52,759 토큰/초에 닿았고, H100은 더 일찍 포화됐어요. 80 GB 메모리가 동시 시퀀스 256 부근에서 한계예요. 레이턴시 비용은 있어요. 시퀀스 512에서 토큰당 출력 시간(TPOT)이 약 192 ms로 배치 워크로드엔 괜찮아요. 1,024로 밀면 처리량 증가 없이 331 ms까지 올라서, 배치 서빙의 실용 상한은 512이고 인터랙티브 레이턴시가 필요하면 256이 나아요.
그래서 GPU를 어떻게 고르나요
우리라면 이 순서로 고르겠어요.
- B 시리즈(B200)부터. 토큰당 비용은 동률이라 결정 기준은 속도와 서빙 용량인데, B200이 둘 다 이겨요. 같은 작업을 훨씬 짧은 시간에 학습하고, A100보다 토큰/초를 10배 넘게 서빙하며, 트래픽이 늘어도 계속 확장할 여유(192 GB, native FP8, FP8 KV 캐시)가 있어요. 대부분의 팀에겐 학습·추론 모두 이게 기본값이에요.
- 그 정도까지 필요 없을 때만 H100으로. 그래도 A100 대비 학습 처리량 2.5배, 추론 처리량 6.5배에 토큰당 훨씬 싸게 서빙해요. B200의 여유가 워크로드에 비해 과할 때 합리적인 중간 단계예요.
- A100은 가장 저렴한 선택지로. 완벽히 튜닝하면 토큰당 학습 비용이 근소하게 가장 낮지만, 가장 느리고 native FP8 경로가 없고 80 GB가 낮은 동시성에서 포화돼서 신형 카드의 추론 수치엔 못 닿아요. 예산이 빠듯하거나 레이턴시에 관대한 학습엔 좋지만, 프로덕션 추론 자리는 아니에요.
- 하나가 아니라 여러 GPU로 확장하세요. 여기 모든 수치는 8-GPU 결과예요. 가장 싼 학습 설정도 FSDP가 모델을 8개 GPU에 샤딩하기 때문에 경계선에 닿고, 가장 큰 추론 이득(높은 동시성, 8,000 시퀀스를 넘는 FP8 KV 캐시 확장)도 여러 GPU로 서빙할 때만 나와요. 단일 GPU는 31B 모델을 넉넉히 담지도 못하고, 이 처리량의 대부분을 놓쳐요. 이 경제성을 실제로 얻으려면 멀티 GPU 노드(노드당 최대 8 GPU)로 가세요.
이 셋 말고 다른 하드웨어를 고른다면, 2026년 GPU 선택 가이드가 L40S부터 B300까지 전체 라인업을 워크로드별로 정리해 뒀어요.
맞는 GPU에서, 더 내지 않고 돌리세요
이 모든 것의 관건은 접근성이에요. 최신 칩을, 멀티 GPU 노드로, 필요할 때 쓸 수 있느냐죠. VESSL Cloud가 바로 그걸 위해 만들어졌어요. VESSL AI는 AI 워크로드를 위한 네오클라우드로, 최신 B 시리즈(B200, GB200, B300)를 H100·A100과 한 플랫폼에서, 노드당 최대 8 GPU로 제공하고, Smart Pausing으로 유휴 환경의 과금을 멈춰요. 학습과 프로덕션 추론을 B200급 노드에서 돌리고, 워크로드가 허용할 때만 H100·A100으로 내리고, 세 벤더를 따로 관리하지 않고 여러 GPU로 확장하세요. 빅클라우드와 비용을 견줘 보고 싶다면 네오클라우드와 하이퍼스케일러 GPU 가격 비교도 정리해 뒀어요.
어떤 GPU가 모델과 예산에 맞을지 모르겠다면, 정확한 사양이 없어도 괜찮아요. 워크로드만 알려주시면 현실적인 옵션부터 제안드릴게요. 팀에 문의하기.
자주 묻는 질문
이 정도 크기 모델을 파인튜닝하려면 어떤 GPU가 좋나요?
FP8이면 학습이 항상 싸지나요?
LoRA 어댑터와 speculative decoding을 같이 쓸 수 있나요?
단일 최대 효과의 추론 설정은 무엇인가요?
LoRA랑 풀 파인튜닝은 뭐가 달라요?
참고 자료
- VESSL Cloud Cookbook — gpu-cost-benchmark 레시피 (직접 재현용 스크립트 + 실측 결과)
- Hugging Face의 google/gemma-4-31B-it
- vLLM speculative decoding 문서
- NVIDIA H100 및 NVIDIA B200 제품 페이지
- VESSL Cloud 가격
VESSL AI
뉴스레터 구독
AI 인프라 구축 노하우와 최신 GPU 소식을 매달 보내드려요.